- Extended thinking capabilities 自首次发布以来已有改进,因此在大多数情况下,我们建议使用该功能,而不是专门的 think tool。Extended thinking 提供类似收益,也就是给 Claude 留出空间推理复杂问题,同时有更好的集成和性能。实现细节请参阅我们的 extended thinking 文档。
随着我们持续增强 Claude 的复杂问题解决能力,我们发现了一种特别有效的方法:“think” 工具,它会在复杂任务期间为结构化思考创建专用空间。
这项简单但强大的技术不同于 Claude 新的 “extended thinking” 能力(extended thinking implementation details 见此),下文会解释区别。它显著改善了 Claude 的 agentic tool use 能力,包括遵循 policies、做出一致决策,以及处理多步骤问题,而且实现开销很小。
在这篇文章中,我们会探索如何在不同应用中实现 “think” 工具,并基于经过验证的 benchmark results,为开发者分享实用指导。
什么是 “think” 工具?
通过 “think” 工具,我们赋予 Claude 在得到最终答案之前加入一个额外思考步骤的能力,而且这个步骤有自己指定的空间。
虽然它听起来类似 extended thinking,但这是不同概念。Extended thinking 关注的是 Claude 在开始生成回答之前做什么。使用 extended thinking 时,Claude 会在采取行动之前深入考虑并迭代自己的计划。“think” 工具则用于 Claude 一旦开始生成回答后,添加一步,让它停下来思考自己是否拥有继续前进所需的全部信息。当 Claude 执行长链条工具调用,或与用户进行长时间多步骤对话时,这尤其有帮助。
这使得 “think” 工具更适合以下情况:Claude 无法仅凭用户 query 获得制定回答所需的全部信息,并且需要处理外部信息(例如工具调用结果中的信息)。Claude 使用 “think” 工具执行的推理,不如 extended thinking 所能获得的推理全面,而是更聚焦于模型发现的新信息。
对于更简单的工具使用场景,例如非顺序工具调用或直接的指令遵循,我们建议使用 extended thinking。当你不需要 Claude 调用工具时,extended thinking 也适用于 coding、math 和 physics 等 use cases。“think” 工具更适合 Claude 需要调用复杂工具、在长工具调用链中仔细分析工具输出、在带有详细指南的 policy-heavy environments 中导航,或做出顺序决策的场景,其中每一步都建立在前一步之上,而且错误代价很高。
下面是一个使用来自 τ-Bench 的标准工具规范格式的示例实现:
{
"name": "think",
"description": "Use the tool to think about something. It will not obtain new information or change the database, but just append the thought to the log. Use it when complex reasoning or some cache memory is needed.",
"input_schema": {
"type": "object",
"properties": {
"thought": {
"type": "string",
"description": "A thought to think about."
}
},
"required": ["thought"]
}
}
我们使用 τ-bench(tau-bench)评估了 “think” 工具。τ-bench 是一个综合 benchmark,旨在测试模型在真实客户服务场景中使用工具的能力,其中 “think” 工具是评测标准环境的一部分。
τ-bench 评估 Claude 的能力包括:
- 在与模拟用户的真实对话中导航;
- 一致地遵循复杂客户服务 agent policy guidelines;
- 使用多种工具访问和操作环境数据库。
τ-bench 使用的主要评估指标是 pass^k,它衡量对于给定任务,k 次独立任务试验全部成功的概率,并在所有任务上取平均。不同于其他 LLM evaluations 中常见的 pass@k 指标(衡量 k 次试验中是否至少一次成功),pass^k 评估一致性和可靠性。这些是客户服务应用中的关键品质,因为在那里,一致遵守 policies 至关重要。
我们的评估比较了几种不同配置:
- Baseline(没有 “think” 工具,没有 extended thinking mode)
- 仅 extended thinking mode
- 仅 “think” 工具
- “think” 工具加 optimized prompt(用于 airline domain)
结果显示,当 Claude 3.7 在 benchmark 的 “airline” 和 “retail” 客户服务领域中有效使用 “think” 工具时,带来了显著提升:
- Airline domain:带 optimized prompt 的 “think” 工具在 pass^1 指标上达到 0.570,而 baseline 只有 0.370,相对提升 54%;
- Retail domain:仅 “think” 工具达到 0.812,而 baseline 为 0.783。
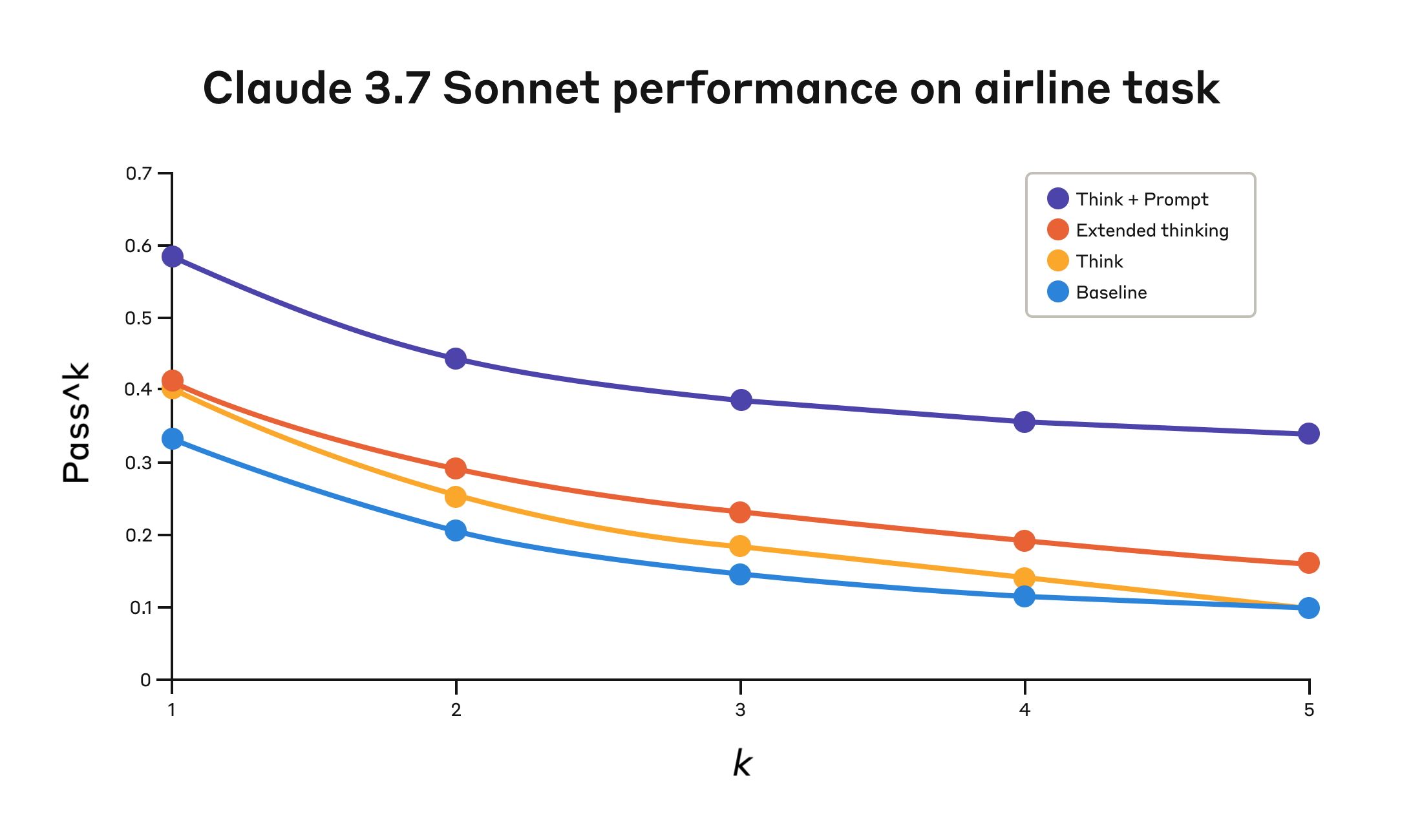
Claude 3.7 Sonnet 在 Tau-Bench eval 的 “airline” domain 中,在四种不同配置下的表现。
| Configuration | k=1 | k=2 | k=3 | k=4 | k=5 |
|---|---|---|---|---|---|
| “Think” + Prompt | 0.584 | 0.444 | 0.384 | 0.356 | 0.340 |
| “Think” | 0.404 | 0.254 | 0.186 | 0.140 | 0.100 |
| Extended thinking | 0.412 | 0.290 | 0.232 | 0.192 | 0.160 |
| Baseline | 0.332 | 0.206 | 0.148 | 0.116 | 0.100 |
四种不同配置的评估结果。分数是比例。
Airline domain 中的最佳表现,是将 “think” 工具与 optimized prompt 配对获得的,该 prompt 给出了在分析客户请求时应使用的推理方法示例。下面是 optimized prompt 的一个例子:
## Using the think tool
Before taking any action or responding to the user after receiving tool results, use the think tool as a scratchpad to:
- List the specific rules that apply to the current request
- Check if all required information is collected
- Verify that the planned action complies with all policies
- Iterate over tool results for correctness
Here are some examples of what to iterate over inside the think tool:
<think_tool_example_1>
User wants to cancel flight ABC123
- Need to verify: user ID, reservation ID, reason
- Check cancellation rules:
* Is it within 24h of booking?
* If not, check ticket class and insurance
- Verify no segments flown or are in the past
- Plan: collect missing info, verify rules, get confirmation
</think_tool_example_1>
<think_tool_example_2>
User wants to book 3 tickets to NYC with 2 checked bags each
- Need user ID to check:
* Membership tier for baggage allowance
* Which payments methods exist in profile
- Baggage calculation:
* Economy class × 3 passengers
* If regular member: 1 free bag each → 3 extra bags = $150
* If silver member: 2 free bags each → 0 extra bags = $0
* If gold member: 3 free bags each → 0 extra bags = $0
- Payment rules to verify:
* Max 1 travel certificate, 1 credit card, 3 gift cards
* All payment methods must be in profile
* Travel certificate remainder goes to waste
- Plan:
1. Get user ID
2. Verify membership level for bag fees
3. Check which payment methods in profile and if their combination is allowed
4. Calculate total: ticket price + any bag fees
5. Get explicit confirmation for booking
</think_tool_example_2>
特别有意思的是不同方法之间的比较。带 optimized prompt 的 “think” 工具显著优于 extended thinking mode(后者表现类似未提示的 “think” 工具)。仅使用 “think” 工具(不加 prompting)相较 baseline 提升了表现,但仍不及 optimized approach。
“think” 工具与 optimized prompting 的组合以显著优势提供了最强表现,这很可能是因为 benchmark 中 airline policy 部分复杂度很高,模型从如何“think”的示例中获益最大。
在 retail domain 中,我们也测试了各种配置,以理解每种方法的具体影响。
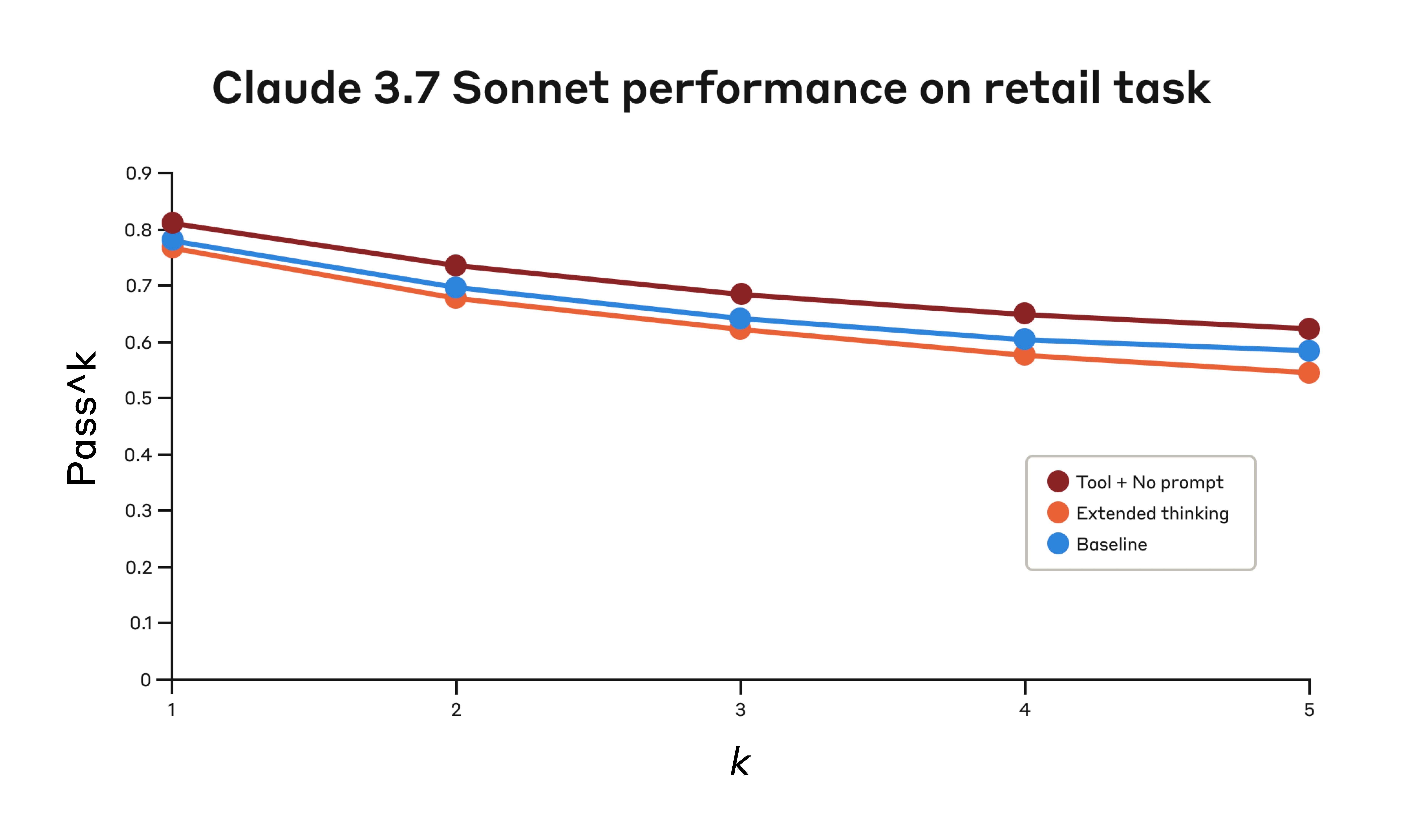
Claude 3.7 Sonnet 在 Tau-Bench eval 的 “retail” domain 中,在三种不同配置下的表现。
| Configuration | k=1 | k=2 | k=3 | k=4 | k=5 |
|---|---|---|---|---|---|
| “Think” + no prompt | 0.812 | 0.735 | 0.685 | 0.650 | 0.626 |
| Extended thinking | 0.770 | 0.681 | 0.623 | 0.581 | 0.548 |
| Baseline | 0.783 | 0.695 | 0.643 | 0.607 | 0.583 |
三种不同配置的评估结果。分数是比例。
“think” 工具即使没有额外 prompting,也取得了最高的 pass^1 分数 0.812。与 airline domain 相比,retail policy 明显更容易导航,Claude 只要有一个思考空间,就能在没有进一步指导的情况下改善表现。
我们的详细分析揭示了几个模式,可以帮助你有效实现 “think” 工具:
- Prompting 在困难领域中非常重要。仅让 “think” 工具可用,可能会在一定程度上改善表现,但将它与 optimized prompting 配对,会在困难领域中带来显著更好的结果。不过,较简单的领域可能仅通过获得 “think” 访问权限就能受益。
- 跨 trials 的一致性提高。使用 “think” 带来的提升在 pass^k 一直到 k=5 时都得以保持,这表明该工具帮助 Claude 更有效处理边界情况和异常场景。
在评估 Claude 3.7 Sonnet 时,我们也向 SWE-bench 设置中加入了类似的 “think” 工具,它对达到 state-of-the-art 分数 0.623 有所贡献。适配后的 “think” 工具定义如下:
{
"name": "think",
"description": "Use the tool to think about something. It will not obtain new information or make any changes to the repository, but just log the thought. Use it when complex reasoning or brainstorming is needed. For example, if you explore the repo and discover the source of a bug, call this tool to brainstorm several unique ways of fixing the bug, and assess which change(s) are likely to be simplest and most effective. Alternatively, if you receive some test results, call this tool to brainstorm ways to fix the failing tests.",
"input_schema": {
"type": "object",
"properties": {
"thought": {
"type": "string",
"description": "Your thoughts."
}
},
"required": ["thought"]
}
}
我们的实验(带 “think” 工具 n=30 samples,不带 n=144 samples)显示,单独加入该工具的效果平均提升了 1.6%(Welch’s t-test: t(38.89) = 6.71, p < .001, d = 1.47)。
基于这些评估结果,我们识别出 Claude 最能从 “think” 工具中受益的具体场景:
- 工具输出分析。 当 Claude 需要在行动前仔细处理此前工具调用的输出,并且可能需要回溯自己的方法时;
- Policy-heavy environments。当 Claude 需要遵循详细指南并验证合规性时;以及
- 顺序决策。当每个动作都建立在此前动作之上,而且错误代价很高时(常见于多步骤领域)。
为了让 Claude 最大化利用 “think” 工具,我们基于 τ-bench 实验推荐以下实现实践。
最有效的方法,是提供关于何时以及如何使用 “think” 工具的清晰说明,例如 τ-bench airline domain 中使用的说明。提供针对你具体 use case 的示例,会显著改善模型使用 “think” 工具的有效性:
- 推理过程中预期的细节程度;
- 如何把复杂指令拆解成可执行步骤;
- 处理常见场景的决策树;以及
- 如何检查所有必要信息是否已被收集。
我们发现,当关于 “think” 工具的说明较长和/或复杂时,把这些说明放在 system prompt 中,比放在工具描述本身中更有效。这种方法提供更广泛的上下文,并帮助模型更好地把思考过程整合进整体行为中。
虽然 “think” 工具可以带来显著提升,但它不适用于所有 tool use use cases,并且会增加 prompt 长度和 output tokens。具体来说,我们发现 “think” 工具在以下 use cases 中不会提供任何提升:
- 非顺序工具调用。如果 Claude 只需要进行单个工具调用,或多个并行调用即可完成任务,那么加入 “think” 不太可能带来任何提升。
- 简单指令遵循。当 Claude 需要遵守的约束不多,且默认行为已经足够好时,额外的 “think”-ing 不太可能带来收益。
“think” 工具是 Claude 实现中的一个直接补充,只需几步就可能产生有意义的改进:
- 用 agentic tool use 场景测试。 从有挑战的 use cases 开始,也就是 Claude 目前在长工具调用链中的 policy compliance 或复杂推理上挣扎的场景。
- 添加工具定义。实现一个针对你的领域定制的 “think” 工具。它需要的代码很少,但能启用更结构化的推理。也可以考虑在 system prompt 中加入何时以及如何使用工具的说明,并加入与你领域相关的示例。
- 监控并 refine。观察 Claude 在实践中如何使用该工具,并调整 prompts,以鼓励更有效的思考模式。
最好的部分是,添加这个工具在性能结果上几乎没有 downside。除非 Claude 决定使用它,否则它不会改变外部行为,也不会干扰你现有的 tools 或 workflows。
我们的研究表明,“think” 工具可以显著增强 Claude 3.7 Sonnet 在复杂任务上的表现,这些任务要求在长工具调用链中遵守 policy 并进行推理。“Think” 不是一刀切方案,但对正确 use cases 来说,它以极低实现复杂度提供了显著收益。
我们期待看到你如何使用 “think” 工具,用 Claude 构建更有能力、更可靠、更透明的 AI systems。
- 虽然我们的 τ-Bench 结果聚焦于 Claude 3.7 Sonnet 通过 “think” 工具获得的提升,但实验显示 Claude 3.5 Sonnet (New) 在与 3.7 Sonnet 相同配置下也能获得性能收益,说明这种提升也可以泛化到其他 Claude models。