在 prompt engineering 成为 applied AI 关注焦点几年之后,一个新术语开始变得突出:context engineering。使用 language models 构建应用,正在逐渐少一些关于为 prompts 找到正确 words 和 phrases 的工作,多一些关于回答更广泛问题的工作:“什么样的 context configuration 最可能生成我们希望 model 表现出的 behavior?”
Context 指的是从 large-language model (LLM) 采样时包含的一组 tokens。手头的 engineering problem,是在 LLMs 的固有限制下优化这些 tokens 的 utility,以持续实现期望 outcome。有效驾驭 LLMs 往往需要 thinking in context,换句话说:考虑 LLM 在任何给定时间可用的整体 state,以及这种 state 可能产生哪些 potential behaviors。
在这篇文章中,我们会探索 context engineering 这一新兴技艺,并为构建 steerable、effective agents 提供一个更精炼的 mental model。
在 Anthropic,我们把 context engineering 视为 prompt engineering 的自然进展。Prompt engineering 指的是为获得最佳 outcomes 而编写和组织 LLM instructions 的方法(可查看 our docs,其中有 overview 和有用的 prompt engineering strategies)。Context engineering 指的是在 LLM inference 期间策划和维护最优 tokens(information)集合的一组 strategies,包括除 prompts 之外也可能进入 context 的所有其他 information。
在使用 LLMs 进行 engineering 的早期,prompting 是 AI engineering work 中最大的组成部分,因为除了日常 chat interactions 之外,大多数 use cases 都需要为 one-shot classification 或 text generation tasks 优化 prompts。顾名思义,prompt engineering 的主要关注点是如何编写有效 prompts,特别是 system prompts。然而,当我们转向 engineering 更有能力、能跨多个 inference turns 和更长 time horizons 运行的 agents 时,我们需要管理整个 context state(system instructions、tools、Model Context Protocol (MCP)、external data、message history 等)的 strategies。
在 loop 中运行的 agent 会生成越来越多 可能 与下一轮 inference 相关的数据,而这些信息必须被 cyclically refined。Context engineering 是从不断演化的 possible information universe 中,策划哪些内容进入有限 context window 的 art and science。
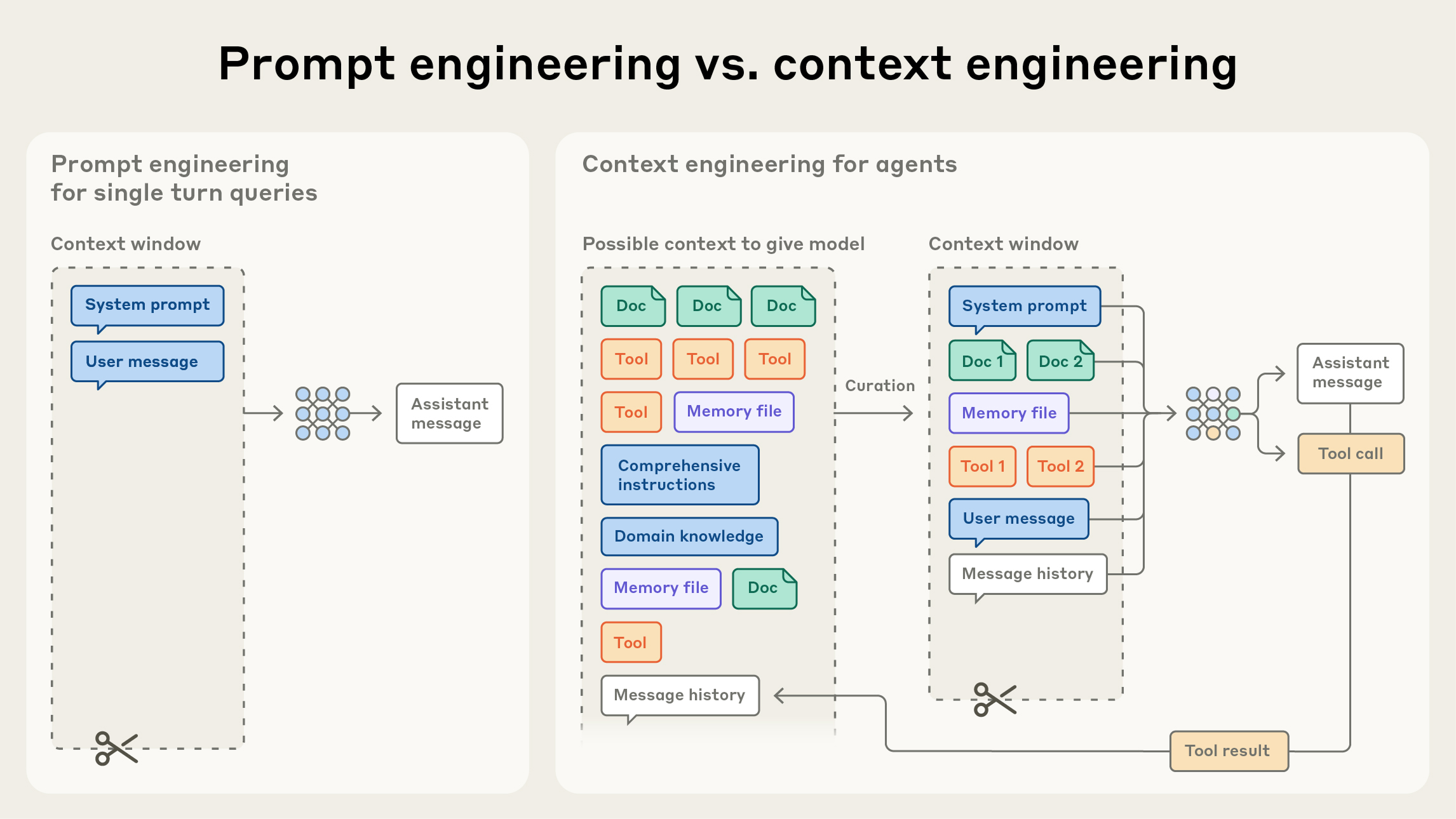
与编写 prompt 这一离散任务不同,context engineering 是 iterative 的;每当我们决定向 model 传递什么时,curation phase 都会发生。
为什么 context engineering 对构建有能力的 agents 很重要
尽管 LLMs 速度很快,也能管理越来越大的 data volumes,但我们观察到,LLMs 和人类一样,到某个点后会失去焦点或产生困惑。关于 needle-in-a-haystack 风格 benchmarking 的研究发现了 context rot 这个概念:随着 context window 中 tokens 数量增加,model 从该 context 中准确 recall information 的能力会下降。
虽然有些 models 的 degradation 比其他 models 更平缓,但这个特征出现在所有 models 中。因此,Context 必须被视为一种具有 diminishing marginal returns 的有限资源。和拥有 limited working memory capacity 的人类一样,LLMs 也有一个在 parsing 大量 context 时使用的 “attention budget”。每引入一个新 token,都会以某种程度消耗这个 budget,从而增加仔细策划 LLM 可用 tokens 的必要性。
这种 attention scarcity 源于 LLMs 的 architectural constraints。LLMs 基于 transformer architecture,它让每个 token 都可以在整个 context 中 attend to every other token。这会为 n 个 tokens 产生 n² 个 pairwise relationships。
随着 context length 增加,model 捕捉这些 pairwise relationships 的能力会被拉薄,从而在 context size 和 attention focus 之间形成自然张力。此外,models 的 attention patterns 来自 training data distributions,而其中 shorter sequences 通常比 longer ones 更常见。这意味着 models 对 context-wide dependencies 的经验更少,专门参数也更少。
像 position encoding interpolation 这样的技术,可以通过把 models 适配到原始训练时较小的 context,让它们处理更长 sequences,尽管 token position understanding 会有一些 degradation。这些因素创造的是 performance gradient,而不是 hard cliff:models 在较长 contexts 中仍然高度 capable,但相比短 contexts 上的表现,可能会在 information retrieval 和 long-range reasoning 上表现出 reduced precision。
这些现实意味着,thoughtful context engineering 对构建有能力的 agents 至关重要。
鉴于 LLMs 受 finite attention budget 约束,好的 context engineering 意味着找到 尽可能小 的 high-signal tokens 集合,使某个 desired outcome 的 likelihood 最大化。实现这个实践说起来容易做起来难,但在下一节中,我们会概述这个 guiding principle 在 context 不同 components 上的实践含义。
System prompts 应该极其清晰,并使用简单、直接的语言,以适合 agent 的 right altitude 呈现 ideas。Right altitude 是两个常见 failure modes 之间的 Goldilocks zone。在一个极端,我们看到 engineers 在 prompts 中 hardcode 复杂、脆弱的 logic,以诱发精确的 agentic behavior。这种方法会产生 fragility,并随着时间增加 maintenance complexity。在另一个极端,engineers 有时会提供 vague、high-level guidance,无法给 LLM 提供关于 desired outputs 的 concrete signals,或错误假定 shared context。最佳 altitude 取得平衡:足够具体以有效引导 behavior,同时又足够灵活,能为 model 提供强 heuristics 来引导 behavior。
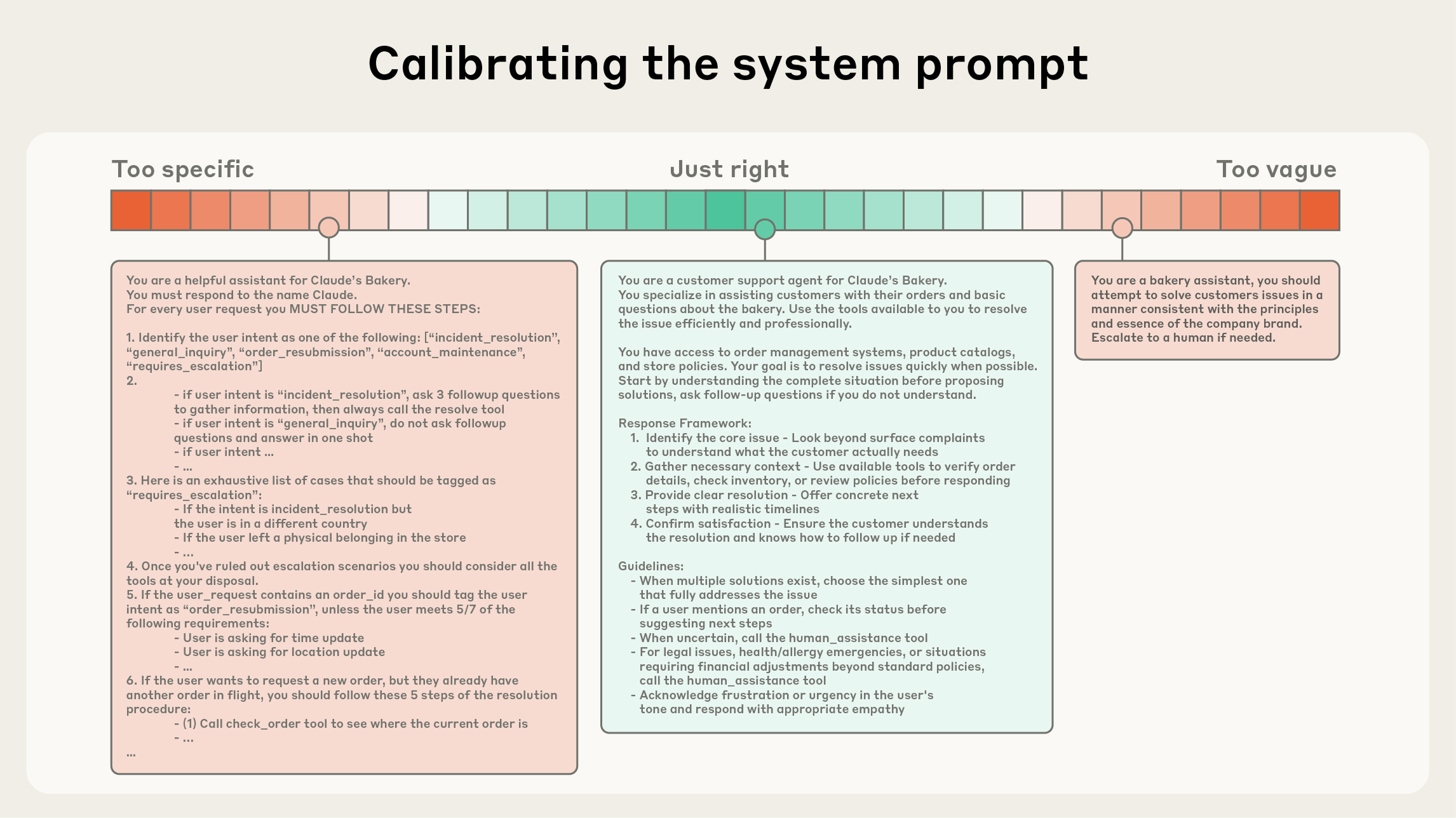
在 spectrum 的一端,我们看到 brittle if-else hardcoded prompts;另一端则是过于 general 或错误假定 shared context 的 prompts。
我们建议把 prompts 组织成不同 sections(例如 <background_information>、<instructions>、## Tool guidance、## Output description 等),并使用 XML tagging 或 Markdown headers 等技术来划分这些 sections,尽管随着 models 变得更有能力,prompts 的具体 formatting 可能会变得不那么重要。
无论你决定如何构造 system prompt,都应该努力追求能够完整勾勒 expected behavior 的最小信息集合。(注意,minimal 不一定意味着 short;你仍然需要预先给 agent 足够信息,确保它遵守 desired behavior。)最佳做法是先用可用的最佳 model 测试一个 minimal prompt,看看它在你的 task 上表现如何,然后根据 initial testing 中发现的 failure modes,添加清晰 instructions 和 examples 来改善 performance。
Tools 允许 agents 与 environment 交互,并在工作中拉取新的 additional context。因为 tools 定义了 agents 与其 information/action space 之间的 contract,所以 tools 推动 efficiency 极其重要,既要返回 token efficient 的信息,也要鼓励 efficient agent behaviors。
在 Writing tools for AI agents – with AI agents 中,我们讨论了构建 LLMs 能很好理解、且功能重叠最少的 tools。类似设计良好的 codebase 中的 functions,tools 应该 self-contained、robust to error,并且在 intended use 上极其清晰。Input parameters 同样应该 descriptive、unambiguous,并发挥 model 的固有 strengths。
我们看到的最常见 failure modes 之一,是 bloated tool sets,它们覆盖过多 functionality,或在该使用哪个 tool 的问题上导致 ambiguous decision points。如果 human engineer 无法明确说出某种情况下应该使用哪个 tool,就不能期待 AI agent 做得更好。正如稍后会讨论的,为 agent 策划一个 minimal viable set of tools,也能在长 interactions 中带来更可靠的 context maintenance 和 pruning。
提供 examples,也就是 few-shot prompting,是一个广为人知且我们仍强烈建议的 best practice。不过,teams 经常会把一长串 edge cases 塞进 prompt,试图阐明 LLM 在特定 task 中应该遵循的每条可能 rule。我们不建议这样做。相反,我们建议努力策划一组 diverse、canonical examples,有效展示 agent 的 expected behavior。对于 LLM 来说,examples 是“胜过千言万语的 pictures”。
我们对 context 的不同 components(system prompts、tools、examples、message history 等)的总体指导,是保持 thoughtful,让你的 context informative 但 tight。现在让我们深入讨论 runtime 时动态检索 context。
Just-in-time context retrieval
在 Building effective AI agents 中,我们强调了 LLM-based workflows 与 agents 的区别。自从写下那篇文章以来,我们越来越倾向于采用一个关于 agents 的 simple definition:LLMs autonomously using tools in a loop。
与客户一起工作时,我们看到这个领域正在向这个 simple paradigm 收敛。随着底层 models 变得更有能力,agents 的 autonomy level 也可以 scale:更聪明的 models 让 agents 能够独立 navigate nuanced problem spaces,并从 errors 中恢复。
我们现在看到 engineers 思考 agent context design 的方式正在发生转变。今天,许多 AI-native applications 使用某种形式的 embedding-based pre-inference time retrieval,为 agent 浮现重要 context 以供 reasoning。随着这个领域转向更 agentic 的方法,我们越来越多地看到 teams 用 “just in time” context strategies 增强这些 retrieval systems。
与其预先处理所有 relevant data,使用 “just in time” 方法构建的 agents 会维护 lightweight identifiers(file paths、stored queries、web links 等),并在 runtime 使用 tools 通过这些 references 动态把 data 加载进 context。Anthropic 的 agentic coding solution Claude Code 使用这种方法,在大型 databases 上执行复杂 data analysis。Model 可以编写 targeted queries、存储 results,并利用 head 和 tail 这样的 Bash commands 分析大量 data,而无需把完整 data objects 加载进 context。这种方法映射了 human cognition:我们通常不会记住整个 corpuses of information,而是引入 file systems、inboxes 和 bookmarks 这样的 external organization 和 indexing systems,按需检索 relevant information。
除了 storage efficiency,这些 references 的 metadata 也提供了一种高效 refine behavior 的机制,无论这种 metadata 是明确提供还是直观存在。对于在 file system 中运行的 agent 来说,tests folder 中名为 test_utils.py 的文件,暗示的 purpose 与位于 src/core_logic/ 中同名文件不同。Folder hierarchies、naming conventions 和 timestamps 都提供重要 signals,帮助 humans 和 agents 理解如何以及何时利用 information。
让 agents 自主 navigate 和 retrieve data 也启用了 progressive disclosure,换句话说,允许 agents 通过 exploration 逐步发现 relevant context。每次 interaction 都会产生 context,告知下一次 decision:file sizes 暗示 complexity;naming conventions 暗示 purpose;timestamps 可以作为 relevance 的 proxy。Agents 可以逐层组装 understanding,只在 working memory 中保留必要内容,并利用 note-taking strategies 获得额外 persistence。这种 self-managed context window 让 agent 聚焦在 relevant subsets 上,而不是淹没在详尽但可能 irrelevant 的 information 中。
当然,这里有一个 trade-off:runtime exploration 比检索 pre-computed data 更慢。不仅如此,还需要有观点且 thoughtful 的 engineering,确保 LLM 拥有正确的 tools 和 heuristics,以有效 navigate 它的信息 landscape。没有适当 guidance 时,agent 可能会通过误用 tools、追逐 dead-ends 或未能识别 key information 来浪费 context。
在某些 settings 中,最有效的 agents 可能会使用 hybrid strategy:预先检索一些 data 以获得 speed,并根据判断进一步进行 autonomous exploration。关于“正确” autonomy level 的 decision boundary 取决于 task。Claude Code 是采用这种 hybrid model 的 agent:CLAUDE.md files 会被 naive 地预先放入 context,而 glob 和 grep 等 primitives 允许它 navigate environment 并 just-in-time retrieve files,从而有效绕过 stale indexing 和 complex syntax trees 的问题。
Hybrid strategy 可能更适合 content 变化较少的 contexts,例如 legal 或 finance work。随着 model capabilities 改善,agentic design 会趋向于让 intelligent models act intelligently,并逐步减少 human curation。鉴于该领域进展迅速,“do the simplest thing that works” 很可能仍然是我们给基于 Claude 构建 agents 的 teams 的最佳建议。
跨越 context 的长期连贯性
Long-horizon tasks 要求 agents 在 action sequences 中维持 coherence、context 和 goal-directed behavior,而这些 sequences 的 token count 会超过 LLM 的 context window。对于持续工作数十分钟到数小时的 tasks,例如大型 codebase migrations 或 comprehensive research projects,agents 需要专门技术来绕过 context window size limitation。
等待更大的 context windows 可能看起来像一个显而易见的 tactics。但在可预见的未来,各种大小的 context windows 很可能都会受到 context pollution 和 information relevance concerns 的影响,至少在需要最强 agent performance 的情况下是这样。为了让 agents 能够在 extended time horizons 中有效工作,我们开发了一些直接处理这些 context pollution constraints 的技术:compaction、structured note-taking 和 multi-agent architectures。
Compaction
Compaction 是把接近 context window limit 的 conversation,总结其 contents,并用 summary 重新初始化一个新 context window 的实践。Compaction 通常是 context engineering 中推动更好 long-term coherence 的第一杠杆。其核心是以 high-fidelity 方式 distill context window 的 contents,让 agent 能够在 minimal performance degradation 下继续。
例如,在 Claude Code 中,我们通过把 message history 传给 model,让它 summarize 并 compress 最关键 details 来实现这一点。Model 会保留 architectural decisions、unresolved bugs 和 implementation details,同时丢弃 redundant tool outputs 或 messages。然后 agent 可以使用这个 compressed context 加上最近访问的五个 files 继续。用户获得 continuity,而不必担心 context window limitations。
Compaction 的艺术在于选择保留什么和丢弃什么,因为过于 aggressive 的 compaction 可能导致 subtle but critical context 丢失,而这些 context 的重要性可能只会在 later 才显现。对于实现 compaction systems 的 engineers,我们建议在复杂 agent traces 上仔细调优 prompt。先最大化 recall,确保 compaction prompt 捕捉 trace 中每一条 relevant information,再迭代提升 precision,消除 superfluous content。
一个 low-hanging superfluous content 的例子是清除 tool calls 和 results:一旦某个 tool 在 message history 深处被调用,为什么 agent 还需要再次看到 raw result?最安全、最轻触的 compaction 形式之一是 tool result clearing,最近已作为 Claude Developer Platform 上的 feature 发布。
Structured note-taking
Structured note-taking,也就是 agentic memory,是一种 agent 定期写 notes,并把 notes 持久化到 context window 外部 memory 的技术。这些 notes 会在之后被拉回 context window。
这种 strategy 以 minimal overhead 提供 persistent memory。像 Claude Code 创建 to-do list,或你的 custom agent 维护 NOTES.md file,这个简单 pattern 允许 agent 在复杂 tasks 中追踪 progress,维护 critical context 和 dependencies,否则这些内容会在数十次 tool calls 后丢失。
Claude playing Pokémon 展示了 memory 如何在 non-coding domains 中转化 agent capabilities。Agent 会在数千个 game steps 中维护精确 tallies,追踪 objectives,例如“过去 1,234 steps 我一直在 Route 1 训练我的 Pokémon,Pikachu 朝着 10 级目标已经提升了 8 级。”在没有任何关于 memory structure 的 prompting 的情况下,它会开发已探索区域的 maps,记住已经解锁的 key achievements,并维护 combat strategies 的 strategic notes,帮助它学习哪些 attacks 对不同 opponents 最有效。
在 context resets 之后,agent 会读取自己的 notes,并继续 multi-hour training sequences 或 dungeon explorations。这种跨 summarization steps 的 coherence,使 long-horizon strategies 成为可能,而如果只把所有信息保留在 LLM 的 context window 中,这是不可能的。
作为 Sonnet 4.5 launch 的一部分,我们在 Claude Developer Platform 上 public beta 发布了 a memory tool,它通过 file-based system 更容易在 context window 外存储和查询 information。这让 agents 能够随时间构建 knowledge bases、跨 sessions 维护 project state,并 reference previous work,而无需把所有内容都保留在 context 中。
Sub-agent architectures
Sub-agent architectures 提供了绕过 context limitations 的另一种方法。与其让一个 agent 试图在整个 project 中维护 state,不如让 specialized sub-agents 使用干净的 context windows 处理 focused tasks。Main agent 用 high-level plan 进行 coordination,而 subagents 执行 deep technical work,或使用 tools 找到 relevant information。每个 subagent 可能会 extensively explore,使用数万 tokens 或更多,但只返回其工作的 condensed、distilled summary(通常为 1,000-2,000 tokens)。
这种方法实现了清晰的 separation of concerns:detailed search context 被隔离在 sub-agents 内部,而 lead agent 专注于 synthesizing 和 analyzing results。这个 pattern 在 How we built our multi-agent research system 中讨论过,它在复杂 research tasks 上相较 single-agent systems 显示了 substantial improvement。
这些方法之间的选择取决于 task characteristics。例如:
- Compaction 为需要大量 back-and-forth 的 tasks 维护 conversational flow;
- Note-taking 擅长有清晰 milestones 的 iterative development;
- Multi-agent architectures 处理复杂 research 和 analysis,在 parallel exploration 有回报时尤其有效。
即便 models 持续改善,在 extended interactions 中维持 coherence 的挑战,仍将是构建更有效 agents 的核心。
Context engineering 代表了我们用 LLMs 构建应用方式的一次根本转变。随着 models 变得更有能力,挑战不只是 crafting the perfect prompt,而是在每一步 thoughtful 地策划哪些 information 进入 model 有限的 attention budget。无论你是在为 long-horizon tasks 实现 compaction、设计 token-efficient tools,还是让 agents just-in-time 探索 environment,guiding principle 都保持不变:找到最小的 high-signal tokens 集合,使 desired outcome 的 likelihood 最大化。
随着 models 改善,我们概述的 techniques 会继续演化。我们已经看到,更聪明的 models 需要更少 prescriptive engineering,让 agents 能以更多 autonomy 运行。但即便 capabilities scale,把 context 视为珍贵、有限的资源,仍将是构建 reliable、effective agents 的核心。
今天就可以在 Claude Developer Platform 上开始使用 context engineering,并通过我们的 memory and context management cookbook 获取有帮助的 tips 和 best practices。
作者:Anthropic 的 Applied AI team:Prithvi Rajasekaran、Ethan Dixon、Carly Ryan 和 Jeremy Hadfield,并感谢团队成员 Rafi Ayub、Hannah Moran、Cal Rueb 和 Connor Jennings 的贡献。特别感谢 Molly Vorwerck、Stuart Ritchie 和 Maggie Vo 的支持。