像 SWE-bench 和 Terminal-Bench 这样的 agentic coding benchmarks,常被用于比较 frontier models 的 software engineering capabilities,而 leaderboards 上的头部名次往往只相差几个百分点。这些分数经常被视为 relative model capability 的精确测量,并且越来越多地影响关于部署哪些 models 的决策。然而,我们发现,仅 infrastructure configuration 就能产生超过这些 margin 的差异。在内部实验中,Terminal-Bench 2.0 上资源最多和资源最少 setup 之间的差距为 6 个百分点(p < 0.01)。
Static benchmarks 会直接给 model 的 output 打分,runtime environment 不会影响结果。Agentic coding evals 则不同:models 会获得一个完整 environment,在其中编写 programs、运行 tests、安装 dependencies,并跨多轮迭代。Runtime 不再是一个 passive container,而是 problem-solving process 的 integral component。两个拥有不同 resource budgets 和 time limits 的 agents,并不是在参加同一场 test。
Eval developers 已经开始考虑这一点。例如,Terminal-Bench 2.0 在最新 2.0 release 中,为每个 task 指定了推荐 CPU 和 RAM。然而,指定 resources 并不等于一致地 enforce 它们。此外,我们发现 enforcement methodology 会改变 benchmark 最终实际测量的东西。
我们是怎么走到这里的
我们在 Google Kubernetes Engine cluster 上运行 Terminal-Bench 2.0。校准 setup 时,我们注意到自己的 scores 与 benchmark 的官方 leaderboard 不匹配,而且 infra error rates 高得惊人:多达 6% 的 tasks 因 pod errors 失败,而其中大多数与 model 解决 tasks 的能力无关。
Scores 的差异归结于 enforcement。我们的 Kubernetes implementation 把每个 task 的 resource specs 既视为 floor,也视为 hard ceiling:每个 container 被 guaranteed 指定 resources,但一旦超过就会被 kill。Container runtimes 通过两个独立 parameters enforce resources:一个 guaranteed allocation,也就是预先 reserved 的 resources;一个 hard limit,到达时 container 会被 kill。当这两个被设置为相同值时,transient spikes 没有任何 headroom:瞬时 memory fluctuation 可能 OOM-kill 一个本来会成功的 container。为了解决这一点,Terminal-Bench 的 leaderboard 使用了不同的 sandboxing provider,其 implementation 更宽松,允许 temporary overallocation 而不终止 container,以优先保证 infrastructural stability。
这个发现引出了一个更大的问题:resource configuration 对 evaluation scores 的影响有多大?
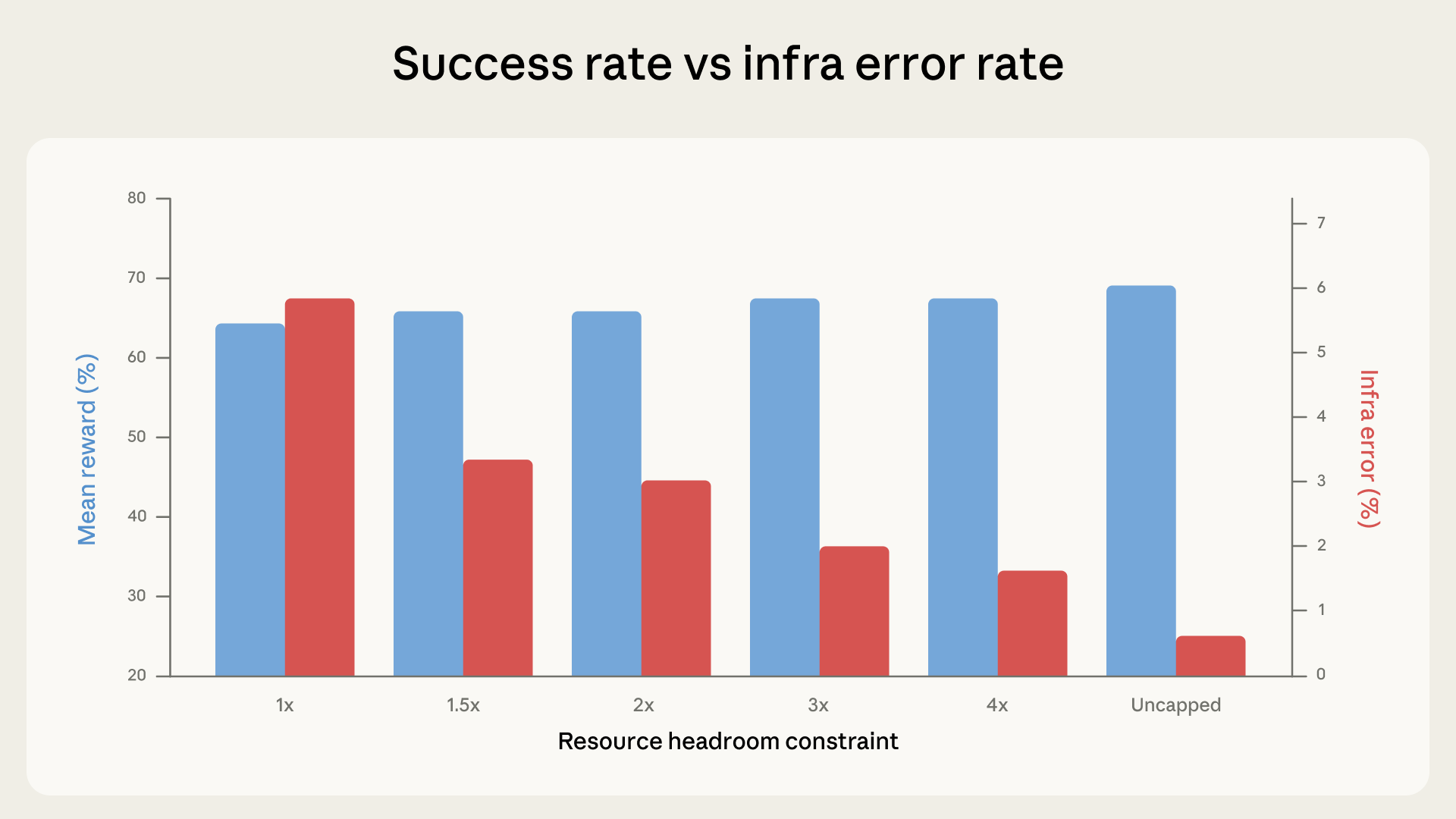
为了量化 scaffold 的影响,我们在六种 resource configurations 下运行 Terminal-Bench 2.0,从严格 enforce 每个 task specs(1x),让它们同时作为 floor 和 ceiling,到完全 uncapped。其他一切保持不变:相同 Claude model、相同 harness、相同 task set。
在我们的实验中,success rates 随 resource headroom 增加而上升。这主要由 infra error rates 在每一步单调下降驱动,从 strict enforcement 下的 5.8% 降到 uncapped 时的 0.5%。从 strict enforcement 到 3x headroom 的下降(5.8% 到 2.1%)在 p < 0.001 下显著。Headroom 越多,因超过 allocation 而被 kill 的 containers 越少。
从 1x 到 3x,success scores 在 noise margin 内波动(p=0.40)。大多数在 1x 崩溃的 tasks 无论如何都会失败,这是我们在 data 中观察到的情况。Agent 探索、撞上 resource wall 并被 preempted,但它本来就不在通向正确 solution 的路径上。
然而,从大约 3x 开始,这个 trend 发生变化:success rates 上升速度快于 infra errors 下降速度。
从 3x 到 uncapped,infra errors 额外下降 1.6 个百分点,而 success 几乎跃升 4 个百分点。额外 resources 让 agent 能尝试只在 generous allocations 下才有效的方法,例如拉取 large dependencies、spawn expensive subprocesses,以及运行 memory-intensive test suites。在 uncapped resources 下,相比 1x 的总提升为 +6 个百分点(p < 0.01)。在边际上,像 rstan-to-pystan 和 compile-compcert 这样的 tasks,在获得 memory headroom 时 success rates 显著改善。
这如何影响测量
到约 3x Terminal-Bench specs 为止,额外 resources 修复的是 infrastructure reliability problems,即 transient resource spikes。Terminal-Bench maintainers 使用的 sandboxing provider 在幕后隐式地做了这件事;eval 变得更稳定,但没有变得更容易。
然而,超过 3x mark 后,额外 resources 开始主动帮助 agent 解决此前无法解决的问题,这表明 limits 实际上可以改变 eval 测量的内容。Tight limits 会无意中奖励非常 efficient strategies,而 generous limits 更宽容,并奖励能更好利用所有可用 resources 的 agents。
一个非常快速编写 lean、efficient code 的 agent,在 tight constraints 下会表现很好。一个用 heavyweight tools brute-force solutions 的 agent,在 generous constraints 下会表现很好。两者都是 legitimate 的测试对象,但如果不指定 resource configuration 就把它们压缩成单一 score,会让差异以及 real-world generalizability 难以解释。
在 bn-fit-modify 上,这是一个需要 Bayesian network fitting 的 Terminal-Bench task,一些 models 的第一步是安装标准 Python data science stack:pandas、networkx、scikit-learn 以及它们的全部 toolchain。在 generous limits 下,这可以奏效。在 tight limits 下,pod 会在 installation 期间 out of memory,在 agent 写下第一行 solution code 之前就失败。存在一种更 lean 的 strategy(只用 standard library 从零实现 math),一些 models 确实默认使用它。另一些不会。不同 models 有不同 default approaches,而 resource configuration 决定了哪些 approaches 恰好成功。我们在不同 Anthropic models 上复制了核心发现。Effect 的方向是一致的,但 magnitude 有所变化。同样的 trends 似乎也适用于 Claude 之外的 models,但我们还没有严格测试它们。
我们还通过在 SWE-bench 上运行 crossover experiment,测试这种 pattern 是否适用于 Terminal-Bench 之外的 evals。我们在 227 个 problems 上以每个 10 samples 的方式,把 total available RAM 最高变化到 baseline 的 5x。同样的 effect 仍然成立,但 magnitude 更小:Scores 再次随着 RAM 单调增加,但 5x 只比 1x 高 1.54 个百分点。SWE-bench tasks 的 resource-intensive 程度较低,因此预期 effect 较小,但这表明 resource allocation 在那里也不是 neutral 的。
其他 variance 来源
Resource allocation 不是唯一 hidden variable。在某些 configurations 中,time limits 也开始发挥作用。
原则上,evaluation setup 的每个元素都可能影响最终 score,从 cluster health 到 hardware specs,从 concurrency level 到甚至 egress bandwidth。Agentic evals 在构造上是 end-to-end system tests,而这个 system 的任何 component 都可能充当 confounder。例如,我们有 anecdotal observation:pass rates 会随 time of day 波动,可能是因为 API latency 随 traffic patterns 和 incidents 变化。我们没有 formally quantified 这个 effect,但它说明了一个更大的 point:“model capability” 与 “infrastructure behavior” 之间的边界,比单一 benchmark score 所暗示的更模糊。Model provider 可以通过 dedicated hardware 来保护其 eval infrastructure 免受这个影响,但 external evaluators 很难做到同样的事。
Public benchmarks 通常旨在测量纯粹的 model capabilities,但在实践中,它们有与 infrastructure quirks 混淆的风险。有时这可能是 desirable 的,因为它允许 end-to-end testing 整个 stack,但更多时候并非如此。对于旨在公开分享的 coding evals,在多个 times 和多个 days 运行,有助于平均掉 noise。
我们的建议
理想情况是在完全相同的 hardware conditions 下运行每个 eval,包括运行 eval 的 scaffold 和 inference stack,因为这样可以确保 across the board 的完美 reproducibility。然而,这并不总是 practical。
鉴于 container runtimes 实际上通过 guaranteed allocation 和 separate hard kill threshold 来 enforce resources,我们建议 evals 为每个 task 指定这两个 parameters,而不是单个 pinned value。单一 exact spec 会把 guaranteed allocation 设置为等于 kill threshold,留下零 margin:我们在 1x 记录的 transient memory spikes 足以 destabilize eval。分离这两个 parameters 让你可以给 containers 足够 breathing room,避免 spurious OOM kills,同时仍然 enforce hard ceiling 来防止 score inflation。
二者之间的 band 应该校准到 floor 和 ceiling 下的 scores 落在彼此 noise 范围内。例如,在 Terminal-Bench 2.0 中,相比每个 task specs 设置 3x ceiling,把 infra error rates 大约降低了三分之二(5.8% 到 2.1%,p < 0.001),同时 score lift 保持 modest 且完全在 noise 内(p = 0.40)。这是一个合理 tradeoff:infrastructure confounder 在很大程度上被 neutralized,同时没有移除 meaningful resource pressure。确切 multiplier 会随 benchmark 和 task distribution 变化,因此应当报告,但 empirical calibration principle 是通用的。
为什么我们关心
这些发现具有超出 eval infrastructure 的实际后果。Benchmark scores 越来越多地被用作 decision-making inputs,但这种关注度(和依赖度)的增加,并不总是伴随运行和报告方式中相应的 rigor。按今天的情况,leaderboard 上 2 分领先可能反映 genuine capability difference,也可能反映某个 eval 跑在更强硬件上,甚至是在更幸运的 time of day,或者二者兼有。如果没有 published(或 standardized)的 setup configurations,外部很难判断,除非相关方额外付出努力,在 identical conditions 下 reproduce objective results。
对于 Anthropic 这样的 labs,含义是 agentic evals 的 resource configuration 应该被视为 first-class experimental variable,并以与 prompt format 或 sampling temperature 相同的 rigor 进行 documented 和 controlled。对于 benchmark maintainers,发布 recommended resource specs(如 Terminal-Bench 2.0 所做)已经很有帮助,而指定 enforcement methodology 则能弥合我们识别出的 gap。对于任何消费 benchmark results 的人,核心 takeaway 是,agentic evals 上的小分数差异所携带的不确定性,比 reported numbers 的 precision 所暗示的更大,尤其是某些 confounders 实在太难控制。
在 resource methodology 标准化之前,我们的数据表明,leaderboard 上低于 3 个百分点的差异,在 eval configuration 被 documented 和 matched 之前都值得怀疑。Terminal-Bench 中等 resource configurations 范围内观察到的 spread 略低于 2 个百分点。Naive binomial confidence intervals 已经跨越 1-2 个百分点;我们在这里记录的 infrastructure confounders 叠加在其上,而不是包含在其中。在 allocation range 的 extremes,spread 达到 6。
几点领先可能表示真实 capability gap,也可能只是一个更大的 VM。
作者:Gian Segato。特别感谢 Nicholas Carlini、Jeremy Hadfield、Mike Merrill 和 Alex Shaw 的贡献。这项工作反映了多个团队在 coding agents evaluations 上的共同努力。欢迎有兴趣贡献的 candidates 在 anthropic.com/careers 申请。