Claude 现在具备 Research capabilities,可以跨 web、Google Workspace 以及任何 integrations 进行搜索,以完成复杂任务。
这个 multi-agent system 从 prototype 到 production 的历程,教会了我们关于系统架构、工具设计和 prompt engineering 的关键经验。Multi-agent system 由多个 agents(自主使用工具循环工作的 LLMs)协同组成。我们的 Research feature 包含一个 agent,它会根据用户 queries 规划研究过程,然后使用工具创建并行 agents,让它们同时搜索信息。包含多个 agents 的系统会在 agent coordination、evaluation 和 reliability 上引入新的挑战。
这篇文章会拆解对我们有效的原则。我们希望你在构建自己的 multi-agent systems 时也会发现它们有用。
Research work 涉及开放式问题,很难提前预测所需步骤。你无法为探索复杂主题 hardcode 一条固定路径,因为这个过程本质上是动态且 path-dependent 的。人们进行研究时,往往会根据发现持续更新方法,并追随调查过程中出现的线索。
这种不可预测性让 AI agents 特别适合 research tasks。Research 要求在调查展开时具备 pivot 或探索切线联系的灵活性。模型必须自主运行许多轮,并基于中间发现决定要追求哪些方向。线性的 one-shot pipeline 无法处理这些任务。
Search 的本质是压缩:从庞大 corpus 中提炼 insights。Subagents 通过并行运行并拥有自己的 context windows 来促进压缩,它们会同时探索问题的不同方面,然后为 lead research agent 浓缩最重要的 tokens。每个 subagent 还提供 separation of concerns,也就是不同的工具、prompts 和探索轨迹,这减少了 path dependency,并支持彻底、独立的调查。
一旦 intelligence 达到某个阈值,multi-agent systems 就会成为扩展性能的关键方式。例如,虽然个体人类在过去 100,000 年里变得更聪明,但人类社会在信息时代变得指数级更有能力,这是因为我们的集体智能和协调能力。即使是 generally-intelligent agents,作为个体运行时也会面对限制;agents 组成的群体可以完成更多事情。
我们的内部评估显示,multi-agent research systems 尤其擅长 breadth-first queries,也就是需要同时追求多个独立方向的问题。我们发现,在内部 research eval 上,以 Claude Opus 4 作为 lead agent、Claude Sonnet 4 作为 subagents 的 multi-agent system,比 single-agent Claude Opus 4 高出 90.2%。例如,当被要求找出 Information Technology S&P 500 公司所有董事会成员时,multi-agent system 通过把任务分解给 subagents 找到了正确答案,而 single agent system 则因缓慢的顺序搜索而未能找到答案。
Multi-agent systems 有效的主要原因,是它们帮助花费足够多的 tokens 来解决问题。在我们的分析中,有三个因素解释了 BrowseComp evaluation(测试 browsing agents 定位难找信息的能力)中 95% 的性能方差。我们发现 token usage 本身解释了 80% 的方差,另外两个解释因素是 tool calls 数量和模型选择。这个发现验证了我们的架构:通过把工作分布到拥有独立 context windows 的 agents 上,为并行推理增加更多容量。最新 Claude models 是 token use 的巨大效率倍增器,因为升级到 Claude Sonnet 4 所带来的性能增益,大于把 Claude Sonnet 3.7 的 token budget 翻倍。Multi-agent architectures 能有效扩展那些超出 single agents 限制的任务上的 token usage。
这里也有缺点:实践中,这些架构会很快消耗 tokens。在我们的数据中,agents 通常使用的 tokens 约为 chat interactions 的 4 倍,而 multi-agent systems 使用的 tokens 约为 chats 的 15 倍。为了经济可行,multi-agent systems 需要任务价值足够高,能够支付更高性能带来的成本。此外,一些要求所有 agents 共享相同上下文,或涉及 agents 之间大量依赖的领域,目前并不适合 multi-agent systems。例如,大多数 coding tasks 中真正可以并行化的任务少于 research,而且 LLM agents 目前还不擅长实时协调和委派给其他 agents。我们发现,multi-agent systems 在具有高价值、重度并行化、信息超出单个 context window,并且需要接入大量复杂工具的任务上表现出色。
我们的 Research system 使用带 orchestrator-worker pattern 的 multi-agent architecture,其中 lead agent 协调流程,同时委派给并行运行的 specialized subagents。
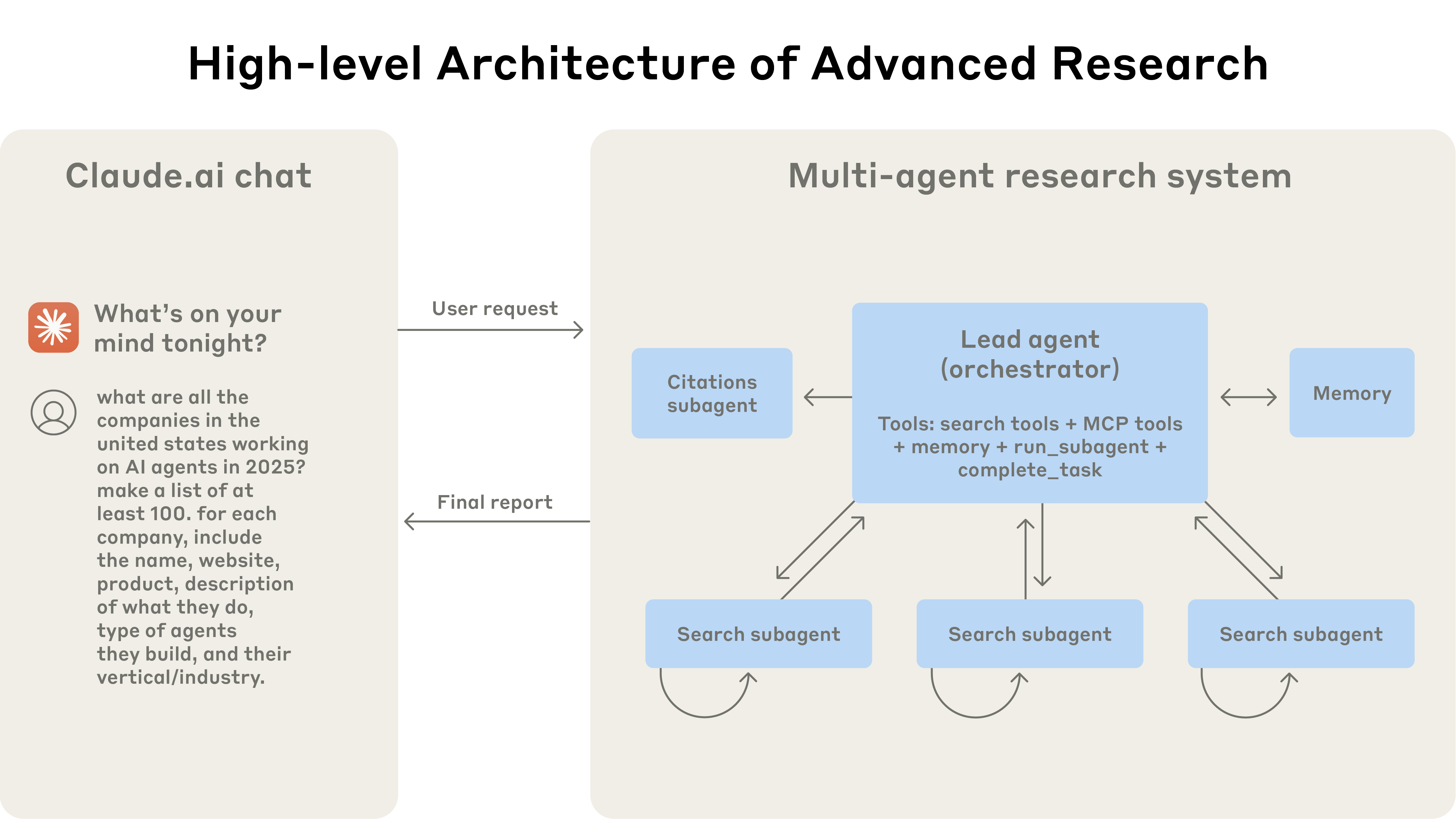
运行中的 multi-agent architecture:用户 queries 流经 lead agent,lead agent 创建 specialized subagents,并行搜索不同方面。
当用户提交 query 时,lead agent 会分析它、制定策略,并生成 subagents 以同时探索不同方面。如上图所示,subagents 通过迭代使用 search tools 收集信息来充当 intelligent filters。在这个例子中,它们研究 2025 年的 AI agent companies,然后向 lead agent 返回公司列表,以便 lead agent 编写最终答案。
传统使用 Retrieval Augmented Generation(RAG)的方法使用 static retrieval。也就是说,它们获取与输入 query 最相似的一组 chunks,并使用这些 chunks 生成回答。相比之下,我们的架构使用 multi-step search,动态寻找相关信息,适应新发现,并分析结果以形成高质量答案。
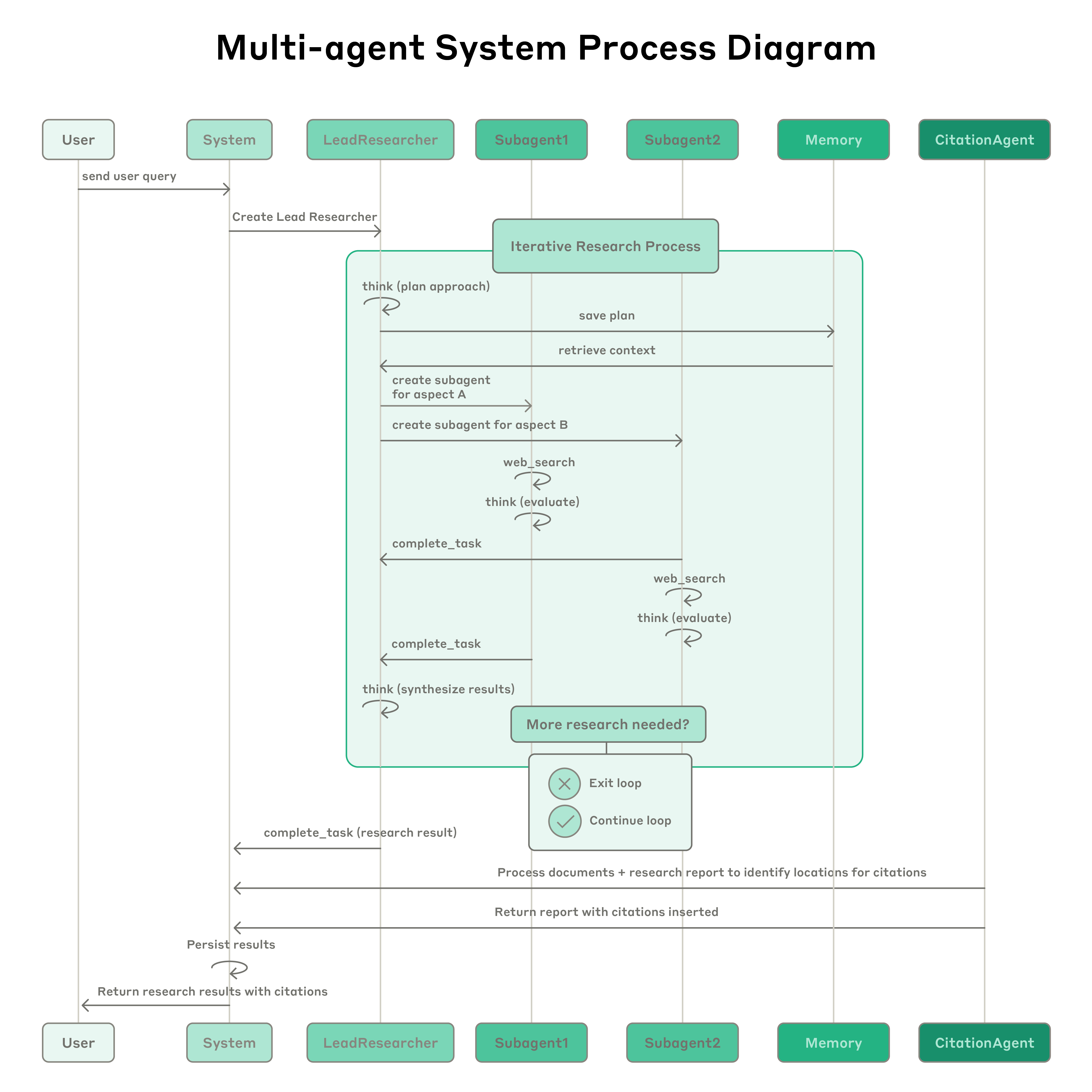
流程图展示了我们 multi-agent Research system 的完整 workflow。当用户提交 query 时,系统会创建一个 LeadResearcher agent,进入迭代式 research process。LeadResearcher 首先思考方法,并把计划保存到 Memory 以持久化上下文,因为如果 context window 超过 200,000 tokens,就会被截断,而保留计划很重要。随后它创建带有具体 research tasks 的 specialized Subagents(这里展示了两个,但可以是任意数量)。每个 Subagent 独立执行 web searches,使用 interleaved thinking 评估工具结果,并把 findings 返回给 LeadResearcher。LeadResearcher 综合这些结果,并决定是否需要更多研究。如果需要,它可以创建额外 subagents 或 refine 策略。一旦收集到足够信息,系统退出 research loop,并把所有 findings 传给 CitationAgent,后者处理 documents 和 research report,以识别引用的具体位置。这确保所有 claims 都能正确归因到 sources。最终,带 citations 的 research results 返回给用户。
Multi-agent systems 与 single-agent systems 有关键差异,包括 coordination complexity 的快速增长。早期 agents 会犯一些错误,例如为简单 queries 生成 50 个 subagents,为不存在的 sources 无休止地搜索 web,以及用过多 updates 互相干扰。由于每个 agent 都由 prompt 引导,prompt engineering 是我们改善这些行为的主要杠杆。下面是我们学到的一些 agent prompting 原则:
- 像你的 agents 一样思考。 为了迭代 prompts,你必须理解它们的效果。为了帮助我们做到这一点,我们使用 Console 构建 simulations,使用系统中的精确 prompts 和 tools,然后逐步观察 agents 工作。这立即暴露出 failure modes:agents 在已经有足够结果时仍继续;使用过于冗长的 search queries;或选择错误工具。有效 prompting 依赖于为 agent 建立准确 mental model,这可以让最有影响力的改动变得显而易见。
- 教 orchestrator 如何委派。 在我们的系统中,lead agent 会把 queries 分解成 subtasks,并把它们描述给 subagents。每个 subagent 都需要 objective、output format、关于工具和 sources 使用的指导,以及清晰的 task boundaries。没有详细 task descriptions,agents 会重复工作、留下缺口,或找不到必要信息。我们一开始允许 lead agent 给出简单、短的指令,例如 “research the semiconductor shortage”,但发现这些指令经常足够模糊,以至于 subagents 误解任务,或执行与其他 agents 完全相同的搜索。例如,一个 subagent 探索 2021 年汽车芯片危机,而另外两个重复调查当前 2025 supply chains,没有有效分工。
- 按 query complexity 调整努力程度。 Agents 难以判断不同任务需要多少努力,所以我们把 scaling rules 嵌入 prompts 中。简单事实查询只需要 1 个 agent 和 3 到 10 次 tool calls;直接比较可能需要 2 到 4 个 subagents,每个 10 到 15 次 calls;复杂 research 可能使用超过 10 个 subagents,并有清晰划分的职责。这些显式指南帮助 lead agent 高效分配资源,避免在简单 queries 上过度投入,这是我们早期版本中的常见失败模式。
- Tool design 和 selection 至关重要。 Agent-tool interfaces 和 human-computer interfaces 一样关键。使用正确工具是高效的,通常也是严格必要的。例如,一个 agent 在 web 上搜索只存在于 Slack 中的上下文,从一开始就注定失败。随着 MCP servers 给模型提供访问外部工具的能力,这个问题会被放大,因为 agents 会遇到从未见过的工具,且工具描述质量差异巨大。我们给 agents 明确 heuristics:例如,先检查所有可用工具;让工具使用匹配用户意图;用 web 做广泛外部探索;或优先使用 specialized tools 而不是 generic ones。糟糕的工具描述可能把 agents 带到完全错误的路径上,所以每个工具都需要 distinct purpose 和 clear description。
- 让 agents 改善自己。 我们发现 Claude 4 models 可以成为优秀的 prompt engineers。当给出 prompt 和 failure mode 时,它们能够诊断 agent 为什么失败并提出改进。我们甚至创建了一个 tool-testing agent:当给它一个有缺陷的 MCP tool 时,它会尝试使用该工具,然后重写工具描述以避免失败。通过测试该工具数十次,这个 agent 找到了关键细节和 bugs。这个改善工具 ergonomics 的过程,让未来 agents 使用新描述时的 task completion time 降低了 40%,因为它们能够避免大多数错误。
- 先宽后窄。 Search strategy 应该模仿专家人类研究:先探索 landscape,再深入 specifics。Agents 往往默认使用过长、过具体的 queries,导致结果很少。我们通过 prompt agents 从短而宽的 queries 开始,评估可用内容,然后逐渐收窄焦点,来抵消这种倾向。
- 引导思考过程。 Extended thinking mode 会让 Claude 在可见 thinking process 中输出额外 tokens,可以作为可控 scratchpad。Lead agent 使用 thinking 规划方法,评估哪些工具适合任务,确定 query complexity 和 subagent count,并定义每个 subagent 的角色。我们的测试显示,extended thinking 改善了 instruction-following、reasoning 和 efficiency。Subagents 也会先规划,然后在工具结果之后使用 interleaved thinking 评估质量、识别缺口并 refine 下一次 query。这让 subagents 更有效地适应任何任务。
- Parallel tool calling 改变速度和表现。 复杂 research tasks 自然涉及探索许多 sources。我们的早期 agents 执行顺序搜索,非常慢。为了速度,我们引入了两种 parallelization:(1)lead agent 并行启动 3 到 5 个 subagents,而不是串行启动;(2)subagents 并行使用 3 个以上工具。这些改动让复杂 queries 的 research time 最多减少 90%,使 Research 可以在几分钟内完成更多工作,而不是花几小时,同时覆盖比其他系统更多的信息。
我们的 prompting strategy 专注于灌输好的 heuristics,而不是 rigid rules。我们研究了熟练人类如何处理 research tasks,并把这些策略编码进 prompts,包括把困难问题分解成更小任务、仔细评估 sources 质量、根据新信息调整搜索方法,以及识别何时该聚焦深度(详细调查一个主题)和何时该追求广度(并行探索许多主题)。我们也通过设置显式 guardrails 主动缓解意外副作用,防止 agents 失控螺旋。最后,我们专注于带 observability 和 test cases 的快速迭代循环。
好的 evaluations 对构建可靠 AI applications 至关重要,agents 也不例外。然而,评估 multi-agent systems 会带来独特挑战。传统 evaluations 往往假定 AI 每次遵循同样步骤:给定输入 X,系统应遵循路径 Y 来产出输出 Z。但 multi-agent systems 不是这样工作的。即使 starting points 完全相同,agents 也可能采取完全不同但有效的路径到达目标。一个 agent 可能搜索三个 sources,另一个可能搜索十个;或者它们可能使用不同工具找到同一个答案。因为我们并不总是知道正确步骤是什么,所以通常无法只检查 agents 是否遵循了我们预先规定的“正确”步骤。相反,我们需要灵活的 evaluation methods,在判断 agents 是否达成正确结果的同时,也判断其过程是否合理。
立刻从小样本开始评估。 在早期 agent development 中,变更通常会产生巨大影响,因为存在大量 low-hanging fruit。一次 prompt tweak 可能把成功率从 30% 提升到 80%。Effect sizes 如此大时,只用几个 test cases 就能看出变化。我们从约 20 个代表真实使用模式的 queries 开始。测试这些 queries 通常能让我们清楚看到改动影响。我们经常听到 AI developer teams 推迟创建 evals,因为他们认为只有包含数百个 test cases 的大型 evals 才有用。然而,最好立刻用几个 examples 开始 small-scale testing,而不是等到能构建更彻底的 evals 时才开始。
LLM-as-judge evaluation 在做好时可以扩展。 Research outputs 很难程序化评估,因为它们是 free-form text,很少有单一正确答案。LLMs 很适合给 outputs 打分。我们使用一个 LLM judge,根据 rubric 中的标准评估每个输出:factual accuracy(claims 是否匹配 sources?)、citation accuracy(引用的 sources 是否匹配 claims?)、completeness(是否覆盖所有被请求方面?)、source quality(是否使用 primary sources 而不是低质量 secondary sources?)以及 tool efficiency(是否使用正确工具且次数合理?)。我们试过用多个 judges 分别评估每个 component,但发现单个 LLM call、单个 prompt,输出 0.0 到 1.0 分数和 pass-fail grade,是最一致且最符合人类判断的方式。当 eval test cases 确实有明确答案时,这种方法尤其有效,我们可以使用 LLM judge 简单检查答案是否正确(例如它是否准确列出了 R&D budgets 前三大的 pharma companies?)。使用 LLM 作为 judge 让我们可以可扩展地评估数百个 outputs。
Human evaluation 会捕捉自动化遗漏的东西。 测试 agents 的人会发现 evals 遗漏的 edge cases。这包括 unusual queries 上的 hallucinated answers、system failures,或微妙的 source selection biases。在我们的案例中,人类 testers 注意到早期 agents 持续选择 SEO-optimized content farms,而不是权威但排名较低的 sources,例如 academic PDFs 或 personal blogs。向 prompts 添加 source quality heuristics 有助于解决这个问题。即使在自动化 evaluations 的世界里,manual testing 仍然必不可少。
Multi-agent systems 会出现 emergent behaviors,也就是没有具体编程却产生的行为。例如,对 lead agent 的小改动可能不可预测地改变 subagents 的行为。成功需要理解 interaction patterns,而不仅是单个 agent behavior。因此,这些 agents 的最佳 prompts 不只是严格指令,而是定义 division of labor、problem-solving approaches 和 effort budgets 的协作框架。做好这件事依赖仔细 prompting 和 tool design、扎实 heuristics、observability,以及紧密 feedback loops。系统中的示例 prompts 请见我们 Cookbook 中的 open-source prompts。
在传统软件中,bug 可能破坏 feature、降低性能或造成 outages。在 agentic systems 中,微小改动会 cascade 成大规模行为变化,这使得为复杂 agents 编写代码非常困难,尤其是这些 agents 必须在长时间运行过程中维护状态。
Agents 是 stateful 的,错误会累积。 Agents 可以长时间运行,在许多 tool calls 中维护状态。这意味着我们需要 durably execute code,并一路处理错误。没有有效缓解措施时,微小系统失败对 agents 可能是灾难性的。当错误发生时,我们不能只是从头重启:重启昂贵,也让用户沮丧。相反,我们构建了可以从 agent 出错时所在位置恢复的系统。我们也使用模型智能优雅处理问题:例如,告诉 agent 某个工具正在失败,并让它适应,效果出奇地好。我们把基于 Claude 构建的 AI agents 的适应性,与 retry logic 和 regular checkpoints 等 deterministic safeguards 结合起来。
Debugging 得益于新方法。 Agents 会做动态决策,而且即使 prompts 相同,运行之间也是 non-deterministic 的。这让 debugging 更困难。例如,用户会报告 agents “找不到显而易见的信息”,但我们看不出原因。Agents 是使用了糟糕 search queries?选择了差 sources?遇到了工具 failures?添加完整 production tracing 后,我们能够诊断 agents 为什么失败,并系统性地修复问题。除了标准 observability,我们还监控 agent decision patterns 和 interaction structures,同时不监控 individual conversations 的内容,以维护用户隐私。这种 high-level observability 帮助我们诊断 root causes、发现意外行为,并修复常见 failures。
Deployment 需要谨慎协调。 Agent systems 是高度 stateful 的 prompts、tools 和 execution logic 之网,几乎持续运行。这意味着每当我们 deploy updates 时,agents 可能处在流程的任何位置。因此,我们需要防止善意代码变更破坏现有 agents。我们不能同时把每个 agent 更新到新版本。相反,我们使用 rainbow deployments 避免打断正在运行的 agents,通过让旧版本和新版本同时运行,并逐步把 traffic 从旧版本转移到新版本。
Synchronous execution 会造成 bottlenecks。 目前,我们的 lead agents 同步执行 subagents,等待每组 subagents 完成后再继续。这简化了协调,但在 agents 之间的信息流中造成 bottlenecks。例如,lead agent 无法 steer subagents,subagents 无法协调,而整个系统可能在等待一个 subagent 完成搜索时被阻塞。Asynchronous execution 可以启用额外并行性:agents 并发工作,并在需要时创建新的 subagents。但这种 asynchronicity 会给 result coordination、state consistency 和 subagents 间 error propagation 带来挑战。随着模型能够处理更长、更复杂的 research tasks,我们预计性能收益会证明这种复杂度是值得的。
构建 AI agents 时,最后一公里往往变成旅程的大部分。能在 developer machines 上工作的 codebases,需要大量工程才能成为可靠 production systems。Agentic systems 中错误的复合性质意味着,传统软件中的小问题可能让 agents 完全偏离轨道。一步失败可能导致 agents 探索完全不同的 trajectories,产生不可预测结果。由于本文描述的所有原因,prototype 和 production 之间的差距往往比预期更宽。
尽管存在这些挑战,multi-agent systems 已证明对开放式 research tasks 有价值。用户说 Claude 帮助他们发现此前没考虑过的商业机会、导航复杂医疗选项、解决棘手技术 bugs,并通过发现他们无法独自找到的 research connections 节省多达数天工作。通过谨慎工程、全面测试、注重细节的 prompt 和 tool design、稳健运营实践,以及对当前 agent capabilities 有强理解的 research、product 和 engineering teams 之间的紧密协作,multi-agent research systems 可以可靠地大规模运行。我们已经看到这些系统正在改变人们解决复杂问题的方式。

一个 Clio embedding plot,展示人们今天使用 Research feature 的最常见方式。排名靠前的 use case categories 包括:跨 specialized domains 开发 software systems(10%)、开发并优化专业和技术内容(8%)、开发 business growth 和 revenue generation strategies(8%)、辅助 academic research 和 educational material development(7%),以及研究并验证关于 people、places 或 organizations 的信息(5%)。
作者:Jeremy Hadfield、Barry Zhang、Kenneth Lien、Florian Scholz、Jeremy Fox 和 Daniel Ford。这项工作反映了 Anthropic 多个团队共同努力,使 Research feature 成为可能。特别感谢 Anthropic apps engineering team,是他们的投入把这个复杂 multi-agent system 带到了 production。我们也感谢早期用户提供的优秀反馈。
下面是关于 multi-agent systems 的一些额外 miscellaneous tips。
对会在许多轮中 mutate state 的 agents 做 end-state evaluation。 评估会在多轮对话中修改持久状态的 agents,会带来独特挑战。不同于 read-only research tasks,每个动作都可能改变后续步骤的环境,创建 dependencies,而传统 evaluation methods 很难处理这些依赖。我们发现,关注 end-state evaluation 而不是 turn-by-turn analysis 更有效。不要判断 agent 是否遵循了特定过程,而是评估它是否达成了正确最终状态。这种方法承认 agents 可能找到到达同一目标的 alternative paths,同时仍确保它们交付预期结果。对于复杂 workflows,把 evaluation 拆成离散 checkpoints,在那里特定 state changes 应该已经发生,而不是试图验证每个 intermediate step。
Long-horizon conversation management。 Production agents 经常进行跨越数百轮的 conversations,需要谨慎的 context management strategies。随着 conversations 延长,标准 context windows 会变得不够用,需要 intelligent compression 和 memory mechanisms。我们实现了一些模式,让 agents 总结已完成工作阶段,并在继续新任务前把 essential information 存储到 external memory。当 context limits 接近时,agents 可以生成带 clean contexts 的 fresh subagents,同时通过谨慎 handoffs 保持连续性。此外,它们可以从 memory 中检索已存储的上下文,例如 research plan,而不是在达到 context limit 时丢失此前工作。这种分布式方法在保持长交互中 conversation coherence 的同时,防止 context overflow。
Subagent output to a filesystem 以减少 “game of telephone”。 对某些类型的结果,direct subagent outputs 可以绕过 main coordinator,从而改善 fidelity 和 performance。不要要求 subagents 通过 lead agent 传达所有东西,而是实现 artifact systems,让 specialized agents 可以创建独立持久化的 outputs。Subagents 调用 tools,把自己的工作存储在 external systems 中,然后把 lightweight references 传回 coordinator。这可以防止 multi-stage processing 中的信息损失,并减少把大型 outputs 复制进 conversation history 所带来的 token overhead。这个模式尤其适合 code、reports 或 data visualizations 这类 structured outputs,因为 subagent 的 specialized prompt 直接产出的结果,往往好于经由 general coordinator 过滤后的结果。