本文由 Tristan Hume 撰写,他是 Anthropic performance optimization team 的负责人之一。Tristan 设计并重新设计了帮助 Anthropic 招聘数十名 performance engineers 的 take-home test。
随着 AI capabilities 改善,评估 technical candidates 变得更困难。一个今天能很好地区分人类技能水平的 take-home,明天可能会被 models 轻松解决,从而对 evaluation 变得毫无用处。
自 2024 年初以来,我们的 performance engineering team 一直使用一个 take-home test,要求 candidates 为模拟 accelerator 优化代码。超过 1,000 名 candidates 完成了它,其中数十人现在在这里工作,包括 bring up 我们的 Trainium cluster,并 shipping 自 Claude 3 Opus 以来每个 model 的 engineers。
但每个新的 Claude model 都迫使我们重新设计这个 test。在给定相同 time limit 时,Claude Opus 4 的表现超过了大多数 human applicants。这仍然让我们能够区分最强 candidates,但随后 Claude Opus 4.5 也匹配了这些人。Human 在给予 unlimited time 时仍然可以 outperform models,但在 take-home test 的 constraints 下,我们已经不再有办法区分 top candidates 的 output 和我们最有能力的 model。
我现在已经迭代了三个版本的 take-home,试图确保它仍然携带 signal。每一次,我都学到了一些关于什么让 evaluations 对 AI assistance robust,以及什么不会的新东西。
这篇文章描述了最初的 take-home design、每个 Claude model 如何击败它,以及为了确保我们的 test 保持领先于 top model capabilities,我不得不采用的越来越不同寻常的方法。虽然我们的工作随着 models 一起演化,但我们仍然需要更多强 engineers,只是需要越来越有创意的方式来找到他们。
为此,我们正在把最初的 take-home 作为 open challenge 发布,因为在 unlimited time 下,最佳 human performance 仍然超过 Claude 能达到的水平。如果你能胜过 Opus 4.5,我们很想听到你的消息,详情在本文底部。
Take-home 的起源
2023 年 11 月,我们正准备训练并发布 Claude Opus 3。我们已经获得了新的 TPU 和 GPU clusters,大型 Trainium cluster 也即将到来,而且我们在 accelerators 上的开销比过去大得多,但我们没有足够的 performance engineers 来应对新的 scale。我 posted on Twitter 请人们给我们发 email,这带来了比我们通过 standard interview pipeline 能评估的更多 promising candidates,而这个流程会消耗 staff 和 candidates 的大量时间。
我们需要一种更高效评估 candidates 的方式。所以,我花了两周设计一个 take-home test,既能充分捕捉这个 role 的要求,也能识别最有能力的 applicants。
Take-homes 名声不好。通常它们充满 generic problems,engineers 觉得无聊,而且作为 filters 表现很差。我的目标不同:创造一些真正 engaging 的东西,让 candidates 愿意参与,并允许我们以高 resolution 捕捉他们的 technical skills。
这个 format 相比 live interviews,在评估 performance engineering skills 时也有优势:
更长 time horizon: Engineers 在 coding 时很少面对少于一小时的 deadline。4 小时窗口(后来缩短为 2 小时)更好地反映了实际工作的 nature。它仍然比大多数真实 tasks 短,但我们需要在这和它的 onerous 程度之间平衡。
真实环境: 没有人盯着看,也不期待 narration。Candidates 可以在自己的 editor 中不受干扰地工作。
理解和 tooling 的时间: Performance optimization 需要理解 existing systems,有时还要构建 debugging tools。二者都很难在普通 50 分钟 interview 中真实评估。
兼容 AI assistance: Anthropic 的 general candidate guidance 要求 candidates 在没有另行说明时完成 take-homes 不使用 AI。对于这个 take-home,我们明确另行说明。
Longer-horizon problems 对 AI 来说更难完全解决,因此 candidates 可以使用 AI tools(就像他们在工作中会使用那样),同时仍然需要展示自己的 skills。
除了这些 format-specific goals,我还应用了设计任何 interview 时使用的相同原则来制作 take-home:
代表真实工作: 问题应该让 candidates 体验这份工作实际涉及什么。
高 signal: Take-home 应该避免依赖单一 insight 的问题,并确保 candidates 有很多机会展示完整能力,尽可能少地交给 chance。它也应该有宽 scoring distribution,并确保有足够 depth,让强 candidates 也不会完成所有内容。
没有特定 domain knowledge: 有良好 fundamentals 的人可以在工作中学习 specifics。要求 narrow expertise 会不必要地限制 candidate pool。
有趣: 快速 development loops、有 depth 的有趣问题,以及创造空间。
我构建了一个用于 fake accelerator 的 Python simulator,其特征类似 TPUs。Candidates 优化在这台 machine 上运行的 code,使用 hot-reloading Perfetto trace 显示每条 instruction,类似于 我们在 Trainium 上拥有的 tooling。
这台 machine 包含让 accelerator optimization 有趣的 features:manually managed scratchpad memory(不同于 CPUs,accelerators 通常需要 explicit memory management)、VLIW(多个 execution units 在每个 cycle 并行运行,需要高效 instruction packing)、SIMD(每条 instruction 对许多 elements 进行 vector operations),以及 multicore(跨 cores 分配工作)。

这个 task 是 parallel tree traversal,并刻意不带 deep learning 风味,因为大多数 performance engineers 当时还没有从事 deep learning,可以在工作中学习 domain specifics。这个问题受到 branchless SIMD decision tree inference 的启发,这是一种 classical ML optimization challenge,算是向过去致意,只有少数 candidates 之前遇到过。
Candidates 从 fully serial implementation 开始,并逐步利用 machine 的 parallelism。Warmup 是 multicore parallelism,然后 candidates 选择处理 SIMD vectorization 或 VLIW instruction packing。最初版本还包含一个 candidates 需要先 debug 的 bug,用来考察他们构建 tooling 的能力。
最初的 take-home 效果很好。Twitter 那批人中有一个人的分数大幅高于其他所有人。他在 2 月初入职,比我们通过 standard pipeline 招到的第一批人晚两周。这个 test 被证明有 predictive value:他立即开始优化 kernels,并找到了一个 launch-blocking compiler bug 的 workaround,该 bug 涉及 tensor indexing math 溢出 32 bits。
在接下来一年半里,大约 1,000 名 candidates 完成了 take-home,它帮助我们招聘了当前 performance engineering team 的大多数成员。对于纸面经验有限的 candidates,它尤其有价值:我们几位表现最好的 engineers 直接来自 undergrad,但在 take-home 中展示了足够 skill,让我们可以有信心 hiring。
反馈是积极的。许多 candidates 因为觉得有趣,工作时间超过了 4 小时限制。最强的 unlimited-time submissions 包含完整的 optimizing mini-compilers,以及几个我没有预料到的巧妙 optimizations。
Claude 赶上来
到 2025 年 5 月,Claude 3.7 Sonnet 已经逐渐达到这样一个点:超过 50% 的 candidates 如果完全委派给 Claude Code,会得到更好结果。随后我在 take-home 上测试了 Claude Opus 4 的 pre-release version。它在 4 小时限制内给出了比几乎所有人类更优化的 solution。
这不是我第一次设计的 interview 被 Claude model 击败。我在 2023 年设计过一个 live interview question,原因是当时我们的问题围绕 common tasks,而早期 Claude models 对这些任务有很多 knowledge,因此可以轻松解决。我试图设计一个比 knowledge 更需要 problem solving skill 的问题,但仍然基于我在工作中解决过的真实(但 niche)问题。Claude 3 Opus 击败了该问题的 part 1;Claude 3.5 Sonnet 击败了 part 2。我们仍在使用它,因为我们的其他 live questions 也不抗 AI。
对于 take-home,有一个直接 fix。这个问题的 depth 远超任何人能在 4 小时内探索完的范围,所以我使用 Claude Opus 4 识别它从哪里开始 struggle。那就成为 version 2 的新 starting point。我写了更干净的 starter code,添加了新的 machine features 来增加 depth,并移除了 multicore(Claude 已经解决了它,而且它只是拖慢 development loops,却没有增加 signal)。
我还把 time limit 从 4 小时缩短到 2 小时。我最初根据 candidate feedback 选择 4 小时,因为他们更希望降低如果卡在 bug 或困惑上就被拖垮的风险,但 scheduling overhead 正在给我们的 pipeline 带来数周延迟。2 小时更容易塞进一个 weekend。
Version 2 强调 clever optimization insights,而不是 debugging 和 code volume。它很好地服务了我们几个月。
当我测试一个 pre-release Claude Opus 4.5 checkpoint 时,我看着 Claude Code 在问题上工作了 2 小时,逐步改善它的 solution。它解决了初始 bottlenecks,实现了所有常见 micro-optimizations,并在不到一小时内达到了我们的 passing threshold。
然后它停了下来,确信自己遇到了不可逾越的 memory bandwidth bottleneck。大多数人类也会得出同样结论。但有一些 clever tricks 可以利用 problem structure 绕过那个 bottleneck。当我告诉 Claude 可以达到的 cycle count 时,它思考了一会儿并找到了 trick。然后它 debug、tune,并实现了进一步 optimizations。到 2 小时 mark 时,它的 score 匹配了该 time limit 内的最佳 human performance,而那位人类也大量使用了 Claude 4 并加以 steering。
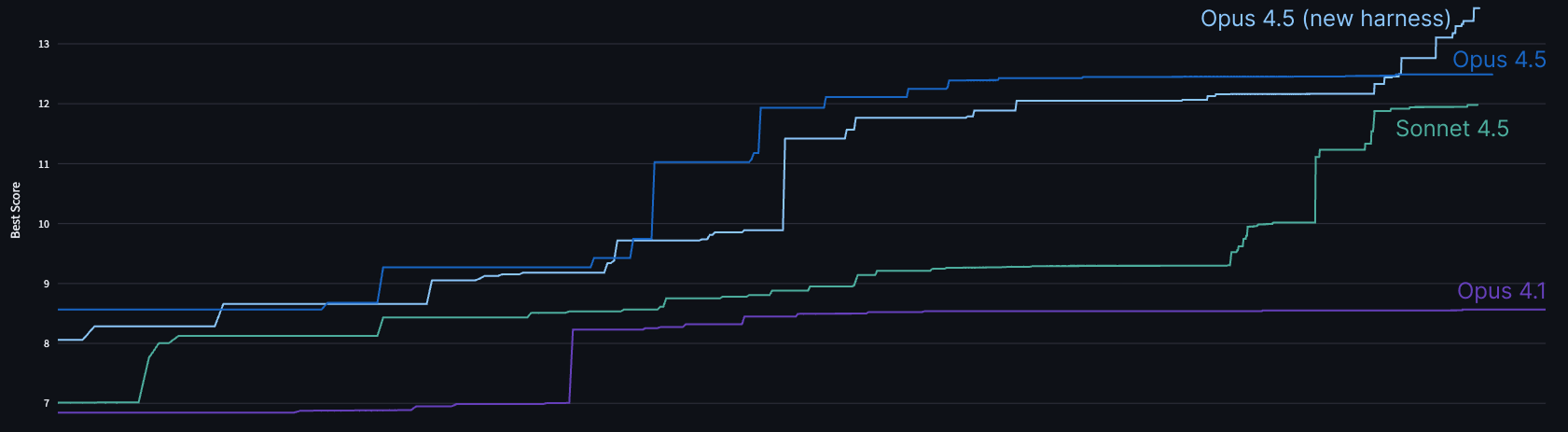
我们在内部 test-time compute harness 中更严谨地试了它,并确认它既可以在 2 小时内击败人类,也可以随着时间继续攀升。发布后,我们甚至以 generic 方式改进了 harness,并获得了更高 score。
我遇到了问题。我们即将发布一个 model,而在我们的 take-home 上,最佳策略将是委派给 Claude Code。
一些同事建议禁止 AI assistance。我不想这么做。除了 enforcement challenges 之外,我有一种感觉:既然人们仍然在我们的工作中发挥重要作用,我应该能找到 某种 方法,让他们在 with AI 的 setting 中区分自己,就像他们在工作中会有的那样。我还不想向 idea 屈服,即人类只在长于几个小时的 tasks 上有优势。
其他人建议把 bar 提高到“substantially outperform what Claude Code achieves alone”。这里的担忧是 Claude 工作很快。人类通常会花 2 小时中的一半阅读并理解问题,然后才开始优化。试图 steer Claude 的人类可能会一直落后,只能事后理解 Claude 做了什么。Dominant strategy 可能变成坐在一边观看。
如今 Anthropic 的 performance engineers 仍然有很多工作要做,但它看起来更像 tough debugging、systems design、performance analysis、弄清楚如何 verify 我们 systems 的 correctness,以及弄清楚如何让 Claude 的 code 更简单、更优雅。不幸的是,如果没有大量时间或 common context,这些东西很难以 objective 方式测试。设计代表工作内容的 interviews 一直很难,但现在比以往更难。
但我也担心,如果我投入设计新的 take-home,要么 Claude Opus 4.5 也会解决它,要么它会变得如此有挑战性,以至于人类不可能在两小时内完成。
寻找新的评估
我意识到 Claude 可以帮助我快速实现我设计的任何内容,这促使我尝试开发一个更难的 take-home。我选择了一个基于我在 Anthropic 做过的更棘手 kernel optimizations 之一的问题:在 2D TPU registers 上进行高效 data transposition,同时避免 bank conflicts。我把它提炼成模拟 machine 上的一个更简单问题,并让 Claude 在不到一天内实现 changes。
Claude Opus 4.5 找到了一个我甚至没想到的很棒 optimization。通过仔细 analysis,它意识到可以 transpose 整个 computation,而不是弄清楚如何 transpose data,并相应地重写了整个 program。
在我的真实 case 中,这不会奏效,所以我 patch 了问题以移除这种 approach。Claude 随后取得进展,但找不到最高效 solution。看起来我找到了新问题,现在只需要希望 human candidates 能足够快地得到它。但我有些挥之不去的怀疑,于是使用 Claude Code 的 “ultrathink” feature 和更长 thinking budgets 再次检查,结果它解决了。它甚至知道修复 bank conflicts 的 tricks。
事后看来,这不是合适的问题。许多 platforms 上的 engineers 都为 data transposition 和 bank conflicts 苦恼过,因此 Claude 有大量 training data 可以借鉴。虽然我是从 first principles 找到 solution 的,但 Claude 可以利用更大的 experience toolbox。
我需要一个 human reasoning 能战胜 Claude 更大 experience base 的问题:足够 out of distribution 的东西。不幸的是,这与我的目标冲突:问题要 recognizably like the job。
我想到自己最喜欢的 unusual optimization problems,最终落在 Zachtronics games 上。这些 programming puzzle games 使用 unusual、highly constrained instruction sets,迫使你以 unconventional ways 编程。例如,在 Shenzhen I/O 中,programs 分布在多个相互通信的 chips 上,每个 chip 只有大约 10 条 instructions 和一两个 state registers。Clever optimization 通常涉及把 state 编码进 instruction pointer 或 branch flags。
我设计了一个新的 take-home,由使用 tiny、heavily constrained instruction set 的 puzzles 组成,优化目标是 minimal instruction count。我实现了一个 medium-hard puzzle,并在 Claude Opus 4.5 上测试。它失败了。我补充了更多 puzzles,并让同事 verify:没有我这么沉浸在问题中的人仍然可以 outperform Claude。
不同于 Zachtronics games,我刻意没有提供 visualization 或 debugging tools。Starter code 只检查 solutions 是否 valid。构建 debugging tools 是被测试内容的一部分:你可以插入精心设计的 print statements,也可以让 coding model 在几分钟内生成 interactive debugger。关于如何投资 tooling 的判断也是 signal 的一部分。
我对新的 take-home 相当满意。它可能比原版 variance 更低,因为它由更多 independent sub-problems 组成。早期结果很有希望:scores 与 candidates 过去工作的 caliber 很好相关,而且我最有能力的同事之一得分高于目前任何 candidate。
我仍然为放弃原版的 realism 和 varied depth 感到遗憾。但 realism 可能已经是我们不再拥有的奢侈品。原版有效,是因为它像真实工作。替代品有效,是因为它模拟了 novel work。
Open challenge
我们正在发布最初的 take-home,供任何人用 unlimited time 尝试。在足够长的 time horizons 上,Human experts 相比当前 models 仍然 retain an advantage。有史以来最快的人类 solution substantially exceeds Claude 即使使用 extensive test-time compute 后达到的水平。
发布版本从 scratch 开始(像 version 1 一样),但使用 version 2 的 instruction set 和 single-core design,因此 cycle counts 与 version 2 可比较。
Performance benchmarks(以 simulated machine 的 clock cycles 衡量):
- 2164 cycles:Claude Opus 4 在 test-time compute harness 中运行 many hours 后
- 1790 cycles:Claude Opus 4.5 在 casual Claude Code session 中,约等于 2 小时内最佳 human performance
- 1579 cycles:Claude Opus 4.5 在我们的 test-time compute harness 中运行 2 小时后
- 1548 cycles:Claude Sonnet 4.5 使用远多于 2 小时的 test-time compute 后
- 1487 cycles:Claude Opus 4.5 在 harness 中运行 11.5 小时后
- 1363 cycles:Claude Opus 4.5 在改进后的 test time compute harness 中运行 many hours 后
在 GitHub 下载。如果你优化到低于 1487 cycles,击败 Claude 发布时的最佳 performance,请带上你的 code 和 resume 发 email 到 performance-recruiting@anthropic.com。
或者,你可以 通过我们的常规流程申请,它使用我们现在 Claude-resistant 的 take-home。我们很好奇它能撑多久。