BERTopic 是 Maarten Grootendorst 在论文 BERTopic: Neural topic modeling with a class-based TF-IDF procedure 中提出的一种主题建模方法。
它的核心不只是“把 BERT 用到主题建模里”,而是把主题建模拆成两个相对独立的问题:
- 哪些文档应该分到一起? 这个问题交给语义嵌入、降维和聚类。
- 这个文档簇应该怎样命名? 这个问题交给 class-based TF-IDF,也就是 c-TF-IDF。
这篇笔记把前面整理的论文摘要和算法可视化合在一起,用几张图拆开说明 BERTopic 的关键算法。
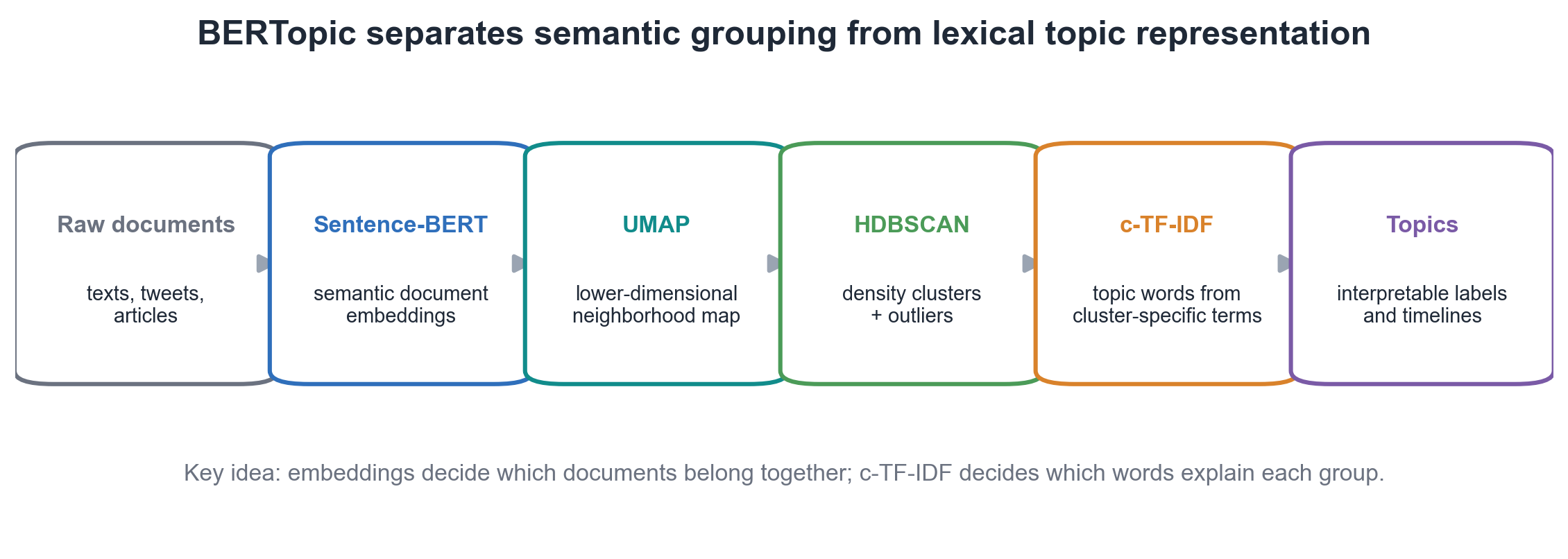
BERTopic 的整体流程可以概括为:
- 用 Sentence-BERT 之类的模型把文档编码成向量;
- 用 UMAP 把高维向量压到更适合聚类的低维空间;
- 用 HDBSCAN 找出密度较高的文档簇,并允许一部分文档作为离群点;
- 把每个簇里的文档拼成一个“大文档”,用 c-TF-IDF 找出最能代表这个簇的词;
- 得到主题、主题关键词,以及随时间或元数据变化的局部主题表示。
为什么不是直接用 LDA?
传统主题模型,比如 LDA 和 NMF,通常把文档看成词袋。词袋表示很好用,但它有一个明显代价:它弱化了词语在上下文中的语义关系。
例如,“car”“vehicle”“Tesla”“self-driving”在不同年代、不同语境下可能指向同一个主题,但词袋模型并不会天然知道这些词在语义空间中靠得很近。
BERTopic 的出发点是:先用预训练语言模型捕捉文档级语义,再把主题表示交给更可解释的词频方法。这样一来,聚类依赖语义,解释仍然落在可读的关键词上。
第一步:文档嵌入
BERTopic 首先将每篇文档转换成向量。论文中使用的是 Sentence-BERT 框架,它能把句子或段落映射到稠密向量空间。
直觉上,如果两篇文档讨论的是同一类事情,它们的向量应该比较接近。比如几条关于 GPU、模型训练、推理性能的文本,应该比关于选举或足球比赛的文本更靠近。
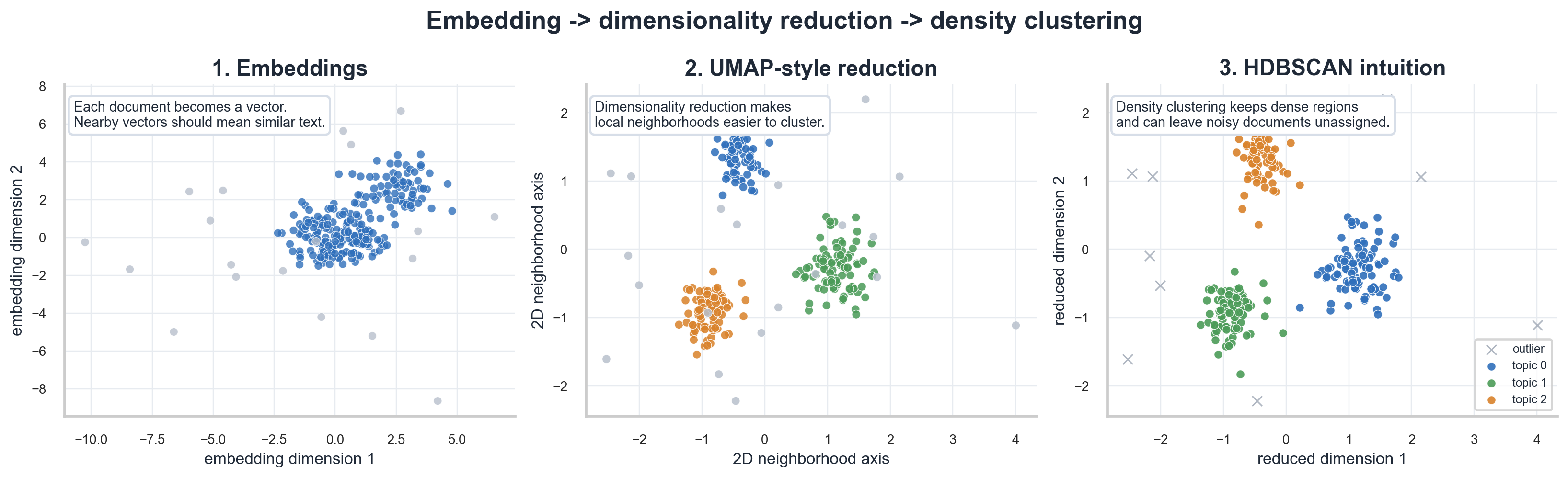
图中左侧展示的是“文档变成向量”的直觉。真实的语言模型嵌入通常有几百甚至上千维,图里只取两个方向做示意。
这里有一个重要设计:BERTopic 不要求某一种固定的嵌入模型。论文中比较了 Universal Sentence Encoder、Doc2Vec、MiniLM 和 MPNet 等模型。结果显示,BERTopic 对嵌入模型具有一定稳定性,不过不同语料上仍会有差异。
第二步:降维
高维空间里,距离会变得不太直观。论文引用了高维距离退化的问题:随着维度上升,最近点和最远点之间的距离差异会变小,聚类会更困难。
因此 BERTopic 在聚类之前先做降维。论文中使用 UMAP,因为它试图在低维空间中保留高维数据的局部和全局结构。
可以把这一步理解为:语言模型已经给每篇文档找到了语义坐标,但这个坐标空间太大;UMAP 负责把它压成更适合聚类的地图。
图中间的面板就是这个过程的示意:原先高维的文档向量被投影到二维后,不同主题的局部邻域变得更清楚。
第三步:密度聚类
降维之后,BERTopic 使用 HDBSCAN 聚类。HDBSCAN 是 DBSCAN 的层次化扩展,它不强制所有点都属于某个簇,也不要求每个簇都是类似球形的结构。
这对主题建模很重要,因为真实文本中总会有一些文档很难归类:
- 它们可能同时谈多个话题;
- 它们可能太短,语义信息不足;
- 它们可能是噪声或边缘案例。
HDBSCAN 允许这些文档成为 outlier,而不是硬塞进某个主题。这也是 BERTopic 相比一些 centroid-based 方法更自然的地方:主题簇不必围绕一个“中心点”形成规则圆球。
不过,这也带来一个实践问题:HDBSCAN 的参数会影响主题数量、离群点数量和主题粒度。BERTopic 的结果不是一个完全确定的“真相”,而是一个需要人工检查和调参的探索工具。
第四步:用 c-TF-IDF 给主题命名
聚类只回答“哪些文档属于同一组”,还没有回答“这一组在讲什么”。
BERTopic 的关键贡献是 c-TF-IDF。它的想法很简单:
- 把同一个簇里的所有文档拼接起来;
- 把这个拼接后的文本看成一个 class;
- 计算某个词在这个 class 中是否足够频繁,同时在其他 class 中是否足够稀有。
普通 TF-IDF 衡量的是一个词对某篇文档的重要性。c-TF-IDF 衡量的是一个词对某个主题簇的重要性。
论文中给出的形式可以理解为:
$$ W_{t,c}=tf_{t,c}\cdot \log(1+\frac{A}{tf_t}) $$
其中 $tf_{t,c}$ 表示词 $t$ 在 class $c$ 中的频率,$A$ 是每个 class 的平均词数,$tf_t$ 是词 $t$ 在所有 class 中的总体频率。
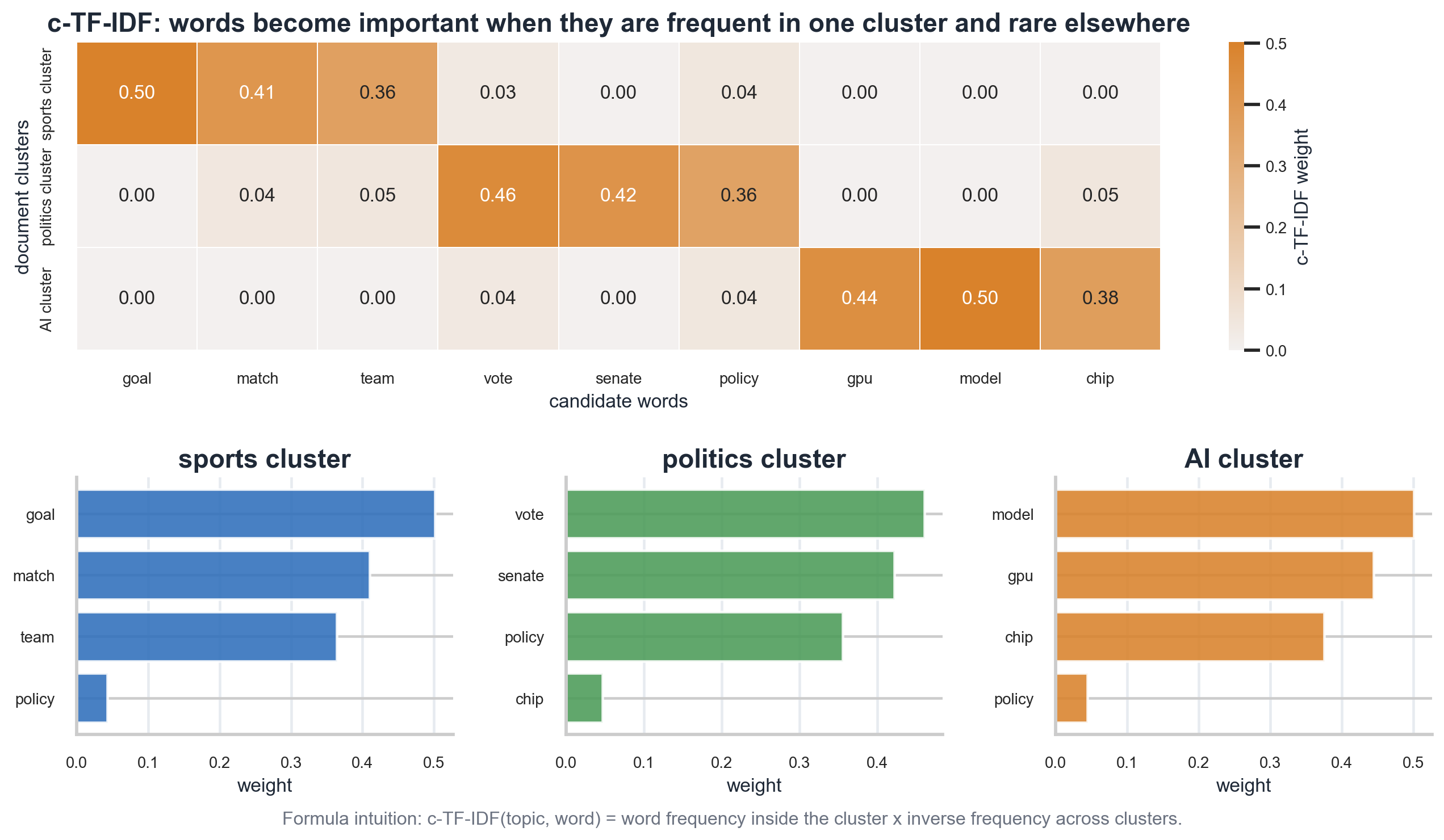
图里的例子有三个簇:sports、politics 和 AI。像 “goal”“match”“team” 在 sports 簇中很高,且不常出现在其他簇,所以会成为 sports 主题的代表词。类似地,“vote”“senate”“policy”代表 politics,“gpu”“model”“chip”代表 AI。
这一步的好处是解释性强:最终给用户看的不是一个不可读的向量,而是一组主题关键词。
它的代价也很清楚:虽然聚类阶段使用了上下文嵌入,主题表示阶段仍然是词袋式的。因此,主题关键词之间可能重复,或者无法直接表达更复杂的语义关系。
第五步:动态主题建模
BERTopic 还可以处理带时间属性的文本集合。论文中的动态主题建模不是每个时间点都重新训练一套主题,而是:
- 先在整个语料上拟合全局主题;
- 再按时间切片,重新计算每个主题在不同时间片下的 c-TF-IDF 表示;
- 可选地对相邻时间片做平滑。
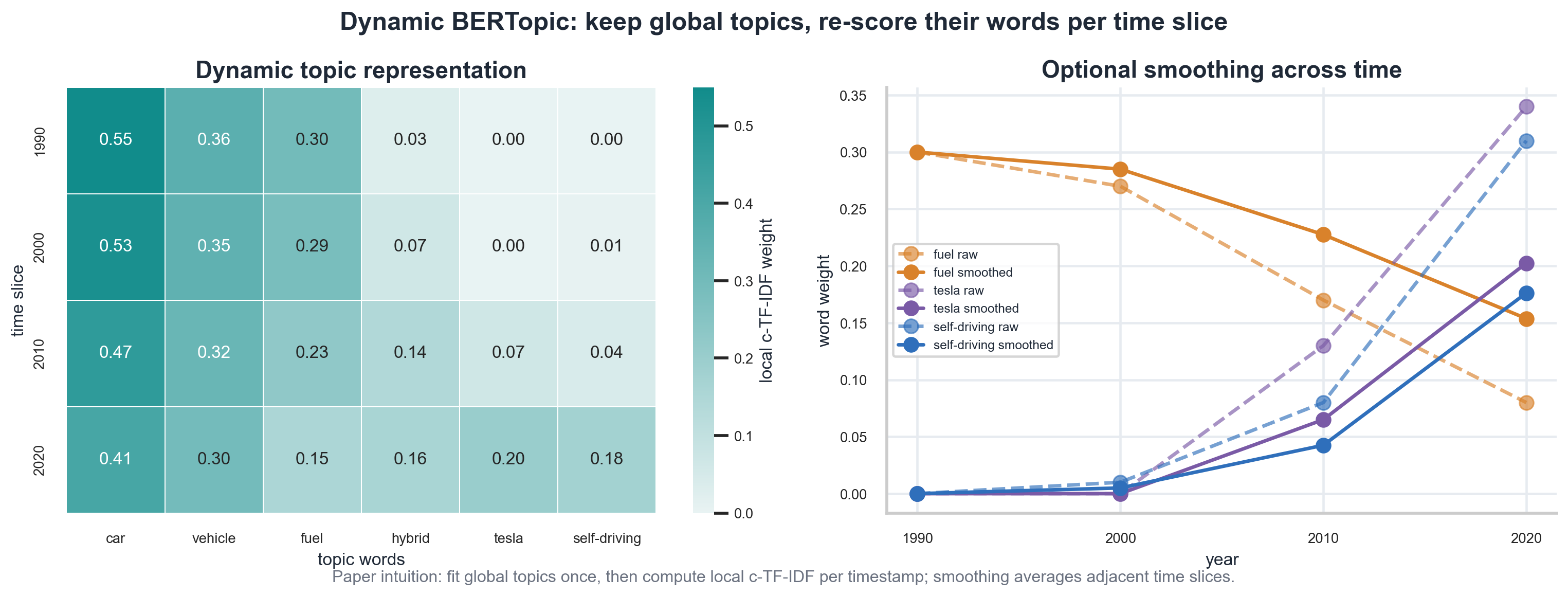
图中用“汽车主题”做示意。1990 年左右,“car”“vehicle”“fuel”可能更重要;到了 2020 年,“tesla”“self-driving”开始变得更突出。
这说明同一个全局主题可以在不同时间下呈现不同的局部关键词。BERTopic 用这种方式避免反复嵌入和聚类,从而让动态主题表示更便宜。
平滑步骤的含义也很直观:如果我们认为主题应该随时间连续变化,那么某一年主题词的权重可以部分继承前一个时间片的信息。论文中也提醒,这种线性演化假设并不总成立,所以它是可选的。
论文中的评估方式
论文主要使用两个指标:
- Topic Coherence:主题关键词之间是否经常共同出现。论文使用 NPMI 衡量。
- Topic Diversity:所有主题的 top words 中,有多少是不重复的。
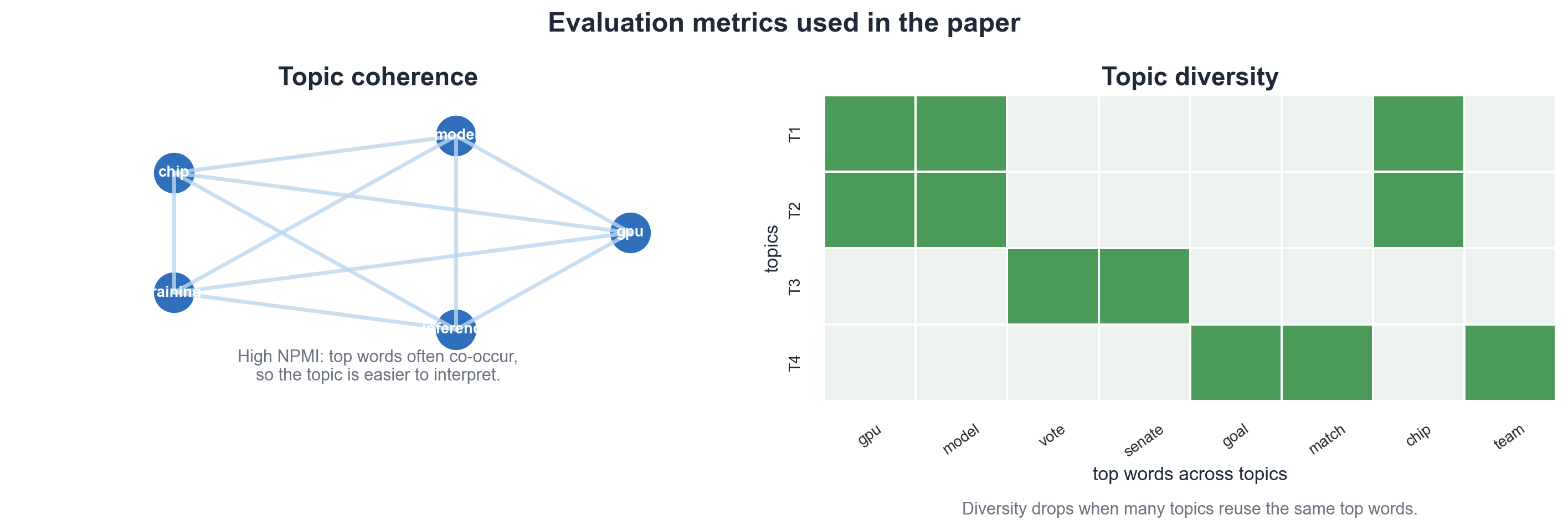
这两个指标分别对应“一个主题内部是否连贯”和“不同主题之间是否足够不同”。
不过要小心:自动指标只是代理。Hoyle 等人在 Is Automated Topic Model Evaluation Broken? 中指出,自动 coherence 指标在神经主题模型上未必可靠对应人类判断。因此,BERTopic 的分数可以作为参考,但不能替代人工解释和任务相关评估。
实验结论
论文在 20 NewsGroups、BBC News 和 Trump tweets 三个数据集上比较了 BERTopic、LDA、NMF、CTM 和 Top2Vec。
几个值得记住的结果是:
- BERTopic 在 topic coherence 上整体具有竞争力,尤其在较短、较嘈杂的 Trump tweets 数据上表现较好。
- CTM 在 topic diversity 上经常更强。
- BERTopic 对不同嵌入模型相对稳定。MiniLM 在速度和效果之间是一个不错折中。
- 对动态主题建模任务,BERTopic 在 Trump 数据上优于 LDA Sequence;在 UN debate 数据上,它的 topic coherence 更高,但 topic diversity 不一定最高。
- 可选的时间平滑在论文实验中没有显著改变 coherence 和 diversity。
换句话说,BERTopic 的优势并不是在每个指标上碾压,而是它把主题建模拆成可替换的模块,使得工程上更灵活。
什么时候适合用 BERTopic?
BERTopic 很适合这些场景:
- 你想探索一批文本中有哪些主题;
- 文本较短,比如 tweets、评论、工单、摘要;
- 你希望主题既利用语义嵌入,又能用关键词解释;
- 你需要按时间、作者、来源等元数据观察主题变化;
- 你愿意人工检查、合并、删除或重命名主题。
它不太适合这些场景:
- 每篇文档天然包含多个主题,而你又不想切分文档;
- 你需要严格可重复、非常稳定的主题边界;
- 你希望模型自动给出完全可靠的分类体系;
- 你的评估只能依赖一个 coherence 分数。
论文也明确提到一个核心弱点:BERTopic 默认假设每篇文档只有一个主题。虽然 HDBSCAN 的 soft clustering 概率可以作为近似,但它并没有从训练过程上真正建模“一篇文档属于多个主题”。
实践建议
如果在真实项目里用 BERTopic,我会按下面的顺序做:
- 先明确分析单位:一篇文档、一段、一句,还是一个窗口。
- 选择合适的 embedding model,并保存 embeddings,避免反复计算。
- 调 UMAP 和 HDBSCAN 参数,观察主题数量和 outlier 比例。
- 用 c-TF-IDF top words 初步理解主题,但不要直接把它当最终标签。
- 人工合并过细主题,删除噪声主题,必要时使用 seed words 或 guided topic modeling。
- 用任务相关标准评估,例如人工编码一致性、下游检索效果、业务可解释性,而不只看 coherence。
BERTopic 最有价值的地方,是它把“语义相似”和“词汇解释”分开了。语义嵌入负责把相似文档聚到一起,c-TF-IDF 负责把每个簇说清楚。这个设计不完美,但很实用,也非常适合做探索式文本分析。