1. 逻辑回归概述
1.1 从线性回归到分类问题
在机器学习中,监督学习主要分为两大类问题:回归问题(Regression)和分类问题(Classification)。
线性回归(Linear Regression)用于预测连续的输出值,例如预测房价、气温等。然而,在实际应用中,我们经常会遇到另一类问题:输出值是离散的类别标签。例如:
- 邮件是否为垃圾邮件?(是 / 否)
- 肿瘤是良性还是恶性?(良性 / 恶性)
- 交易是否存在欺诈?(欺诈 / 正常)
这类问题被称为分类问题。最基础的形式是二分类问题(Binary Classification),即输出只有两个可能的取值,通常编码为 $y \in \lbrace 0,1\rbrace$。
注意: 常见误区
不要试图用线性回归直接解决分类问题。虽然可以尝试用一条直线去拟合 $y \in \lbrace 0,1\rbrace$ 的数据,但这种方法存在严重缺陷:输出值可能远超 [0, 1] 范围,且对异常值极其敏感。逻辑回归就是为了解决这些问题而设计的。
1.2 二分类问题的定义
在二分类问题中,我们的目标是:给定输入特征向量 $x=[x_1,x_2,\ldots,x_n]^T$,预测输出标签 y 的值。
定义: 二分类问题的形式化定义
训练集:$\lbrace (x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),\ldots,(x^{(m)},y^{(m)})\rbrace$,共 $m$ 个训练样本
输入特征:$x^{(i)} \in \mathbb{R}^n$,即每个样本有 $n$ 个特征
输出标签:$y^{(i)} \in \lbrace 0,1\rbrace$
目标:学习一个假设函数 $h_\theta(x)$,使其能够对新样本进行类别预测
逻辑回归的核心思想是:不直接预测类别标签,而是预测 $y=1$ 的概率。也就是说,我们希望模型输出的是一个介于 0 和 1 之间的数值,表示样本属于正类($y=1$)的可能性大小。
2. Sigmoid 函数与概率解释
2.1 Sigmoid 函数的推导
为了让模型输出落在 [0, 1] 区间内,我们需要一个"压缩"函数,将线性组合的输出映射到概率空间。这个函数就是 Sigmoid 函数(也称为 Logistic 函数)。
首先,我们仍然像线性回归一样计算输入特征的线性组合:
$$ z = \vec{w} \cdot \vec{x} + b $$
其中 $w=[w_1,w_2,\ldots,w_n]^T$ 是权重向量,b 是偏置项。为了简化表达,也可以将 b 并入 w,并令 $x_0=1$。
然后,将 z 传入 Sigmoid 函数:
定义: Sigmoid(Logistic)函数
$$ g(z) = \frac{1}{1 + e^{-z}} $$
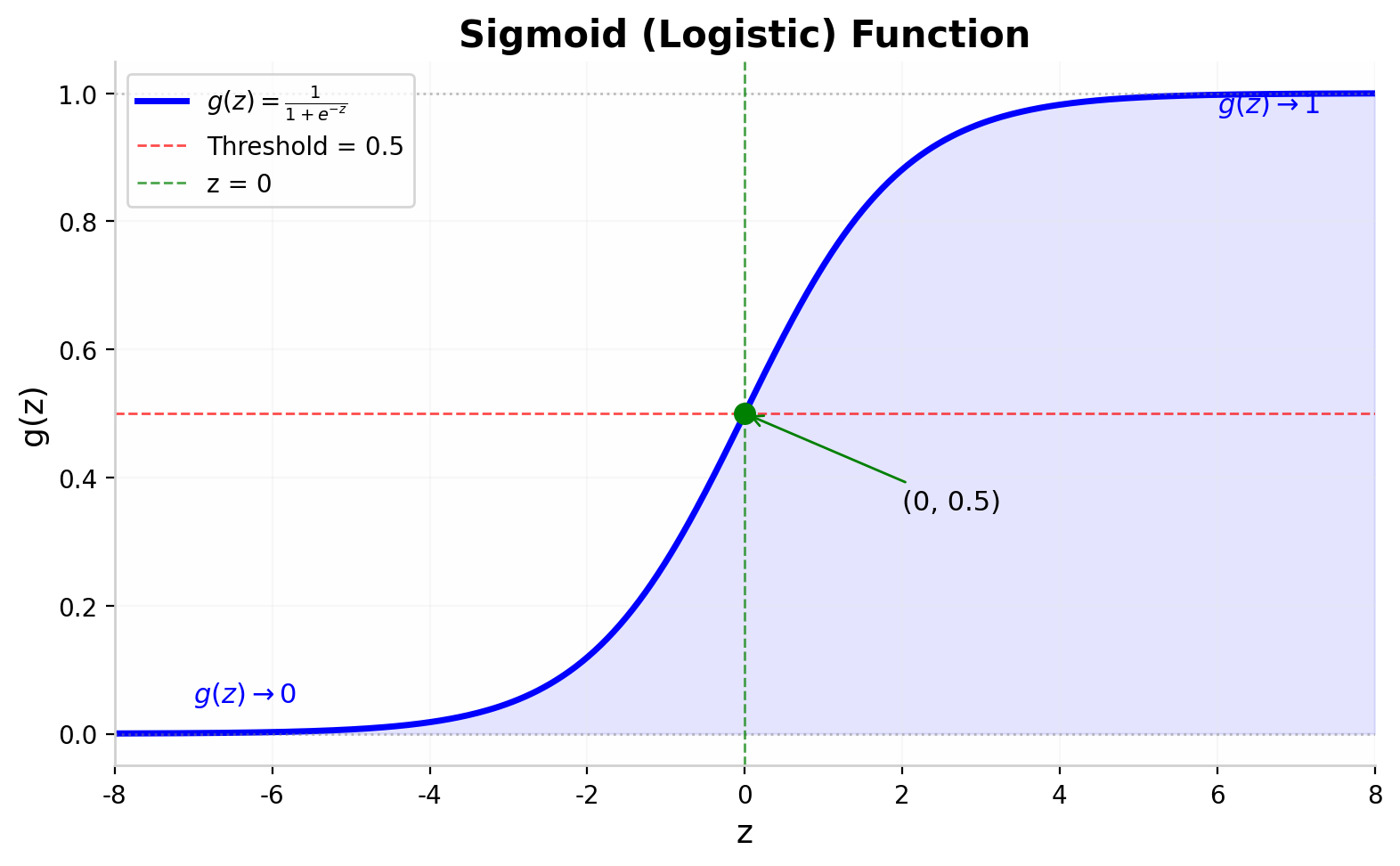
图 1 Sigmoid函数将任意实数 $z$ 映射到 $(0,1)$ 区间。当 $z=0$ 时,$g(0)=0.5$;当 $z\to+\infty$ 时,$g(z)\to 1$;当 $z\to-\infty$ 时,$g(z)\to 0$。红色虚线表示分类阈值 0.5。
因此,逻辑回归的模型公式为:
$$ f(x)=g(\vec{w}\cdot\vec{x}+b)=\frac{1}{1+e^{-(\vec{w}\cdot\vec{x}+b)}} $$
2.2 Sigmoid 函数的性质
Sigmoid 函数具有以下关键性质:
表 1 Sigmoid 函数的性质总结
| 性质 | 说明 | 数学表达 |
|---|---|---|
| 输出范围 | 输出严格介于 0 和 1 之间 | $g(z) \in (0,1)$ |
| 极限行为 | z → +∞ 时趋近于 1 | $\lim_{z\to+\infty} g(z)=1$ |
| 极限行为 | z → -∞ 时趋近于 0 | $\lim_{z\to-\infty} g(z)=0$ |
| 中心对称 | 关于点 (0, 0.5) 中心对称 | $g(-z)=1-g(z)$ |
| 在零点取值 | $z=0$ 时输出恰好为 0.5 | $g(0)=0.5$ |
| 单调递增 | 函数在整个定义域上单调递增 | 随 $z$ 增大而增大 |
笔记: Sigmoid 函数的导数
Sigmoid 函数的导数形式很简洁,在推导梯度下降时会频繁使用,能够极大简化计算。
2.3 概率解释:P(y=1|x)
逻辑回归最强大的地方在于其概率解释。我们将模型的输出直接理解为概率:
定义: 概率解释
$$ f(x)=P(y=1 \mid x;w,b) $$
即:给定输入特征 x 和参数 w, b 的条件下,$y=1$ 的概率。
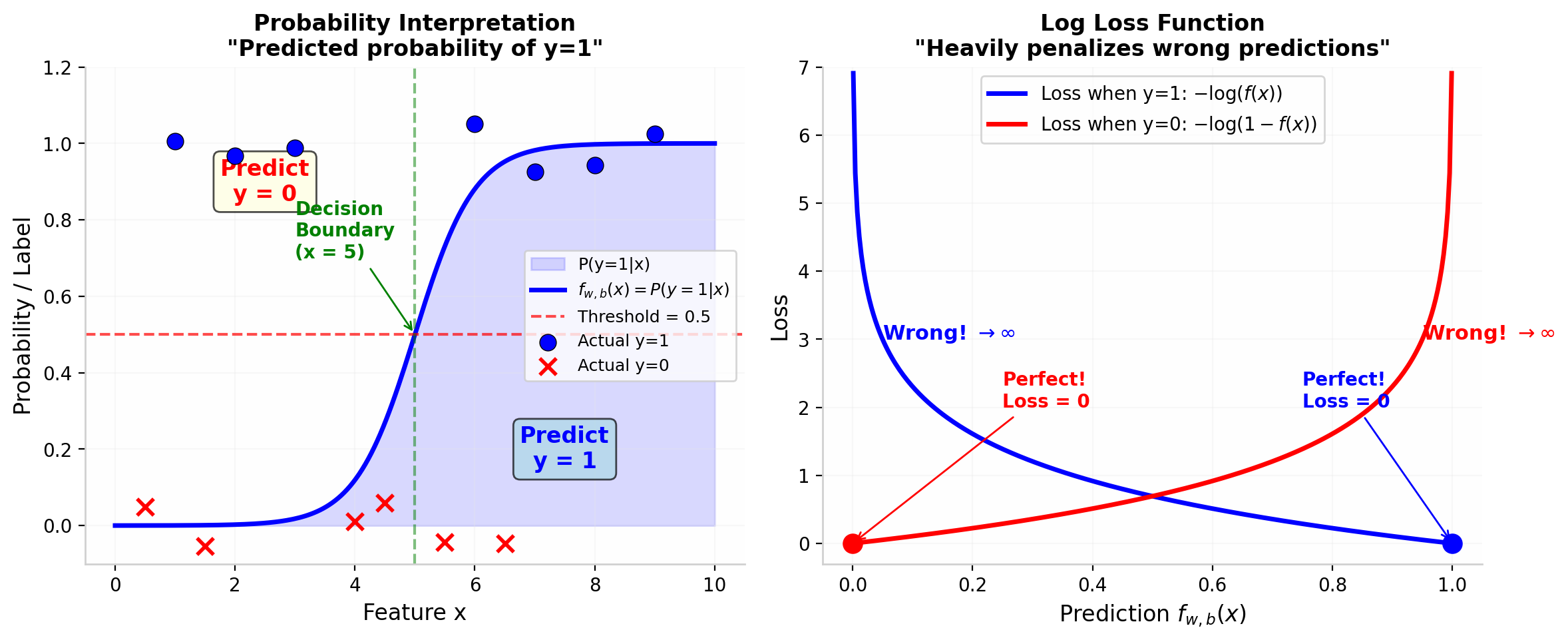
图 2 左图:Sigmoid输出作为概率 P(y=1|x),阈值 0.5 将数据分为两类。右图:对数损失函数在预测正确时损失接近 0,预测错误时损失急剧增大。
当 $f(x)$ 接近 1 时,模型更确信样本属于正类;当 $f(x)$ 接近 0 时,模型更确信样本属于负类。
3. 决策边界
3.1 分类阈值
逻辑回归输出的是概率值 $f(x) \in (0,1)$,但最终我们需要做出一个明确的类别判断:样本到底属于哪一类?
为此,我们引入分类阈值(Classification Threshold),最常用的是 0.5:
定义: 分类决策规则
$$ \hat{y}=1 \text{ if } f(x) \ge 0.5; \quad \hat{y}=0 \text{ if } f(x) < 0.5 $$
由于 Sigmoid 函数是单调递增的,$f(x) \ge 0.5$ 等价于 $\vec{w}\cdot\vec{x}+b \ge 0$。因此决策规则也可以写成:
$$ \hat{y}=1 \text{ if } \vec{w}\cdot\vec{x}+b \ge 0; \quad \hat{y}=0 \text{ if } \vec{w}\cdot\vec{x}+b < 0 $$
笔记: 阈值的选择
0.5 是默认阈值,但并非一成不变。在某些应用场景中(如医疗诊断),我们可能希望降低阈值以提高召回率(不漏掉任何正样本);而在垃圾邮件检测中,可能希望提高阈值以减少误判。阈值的选择需要根据具体业务需求来确定。
3.2 线性决策边界
决策边界是特征空间中将不同类别分开的曲面。在逻辑回归中,决策边界由 $f(x)=0.5$ 定义,即:
$$ \vec{w}\cdot\vec{x}+b=0 $$
当特征只有二维时($x=[x_1,x_2]^T$),决策边界是一条直线:
$$ w_1x_1 + w_2x_2 + b = 0 $$
例子:假设 $w=[1,1]^T$,$b=-3$,则决策边界为 $x_1+x_2-3=0$,即 $x_2=3-x_1$。所有位于直线上方的点满足 $x_1+x_2>3$,被预测为 $y=1$;直线下方的点被预测为 $y=0$。
3.3 非线性决策边界
线性决策边界在很多时候是不够的。例如,当两类数据呈同心圆分布时,直线无法有效分开它们。此时,我们可以通过多项式特征(Polynomial Features)来构建非线性决策边界。
核心思想是:将原始特征进行变换,创造出新的特征。例如,对于二维输入 $[x_1,x_2]$,可以构造:
$$ z = w_1x_1^2+w_2x_2^2+b $$
更一般地,也可以构造包含交叉项的表达式:
$$ z = w_1x_1+w_2x_2+w_3x_1^2+w_4x_1x_2+w_5x_2^2 $$
这些高阶特征会让决策边界从直线扩展为圆、椭圆或其他二次曲线。
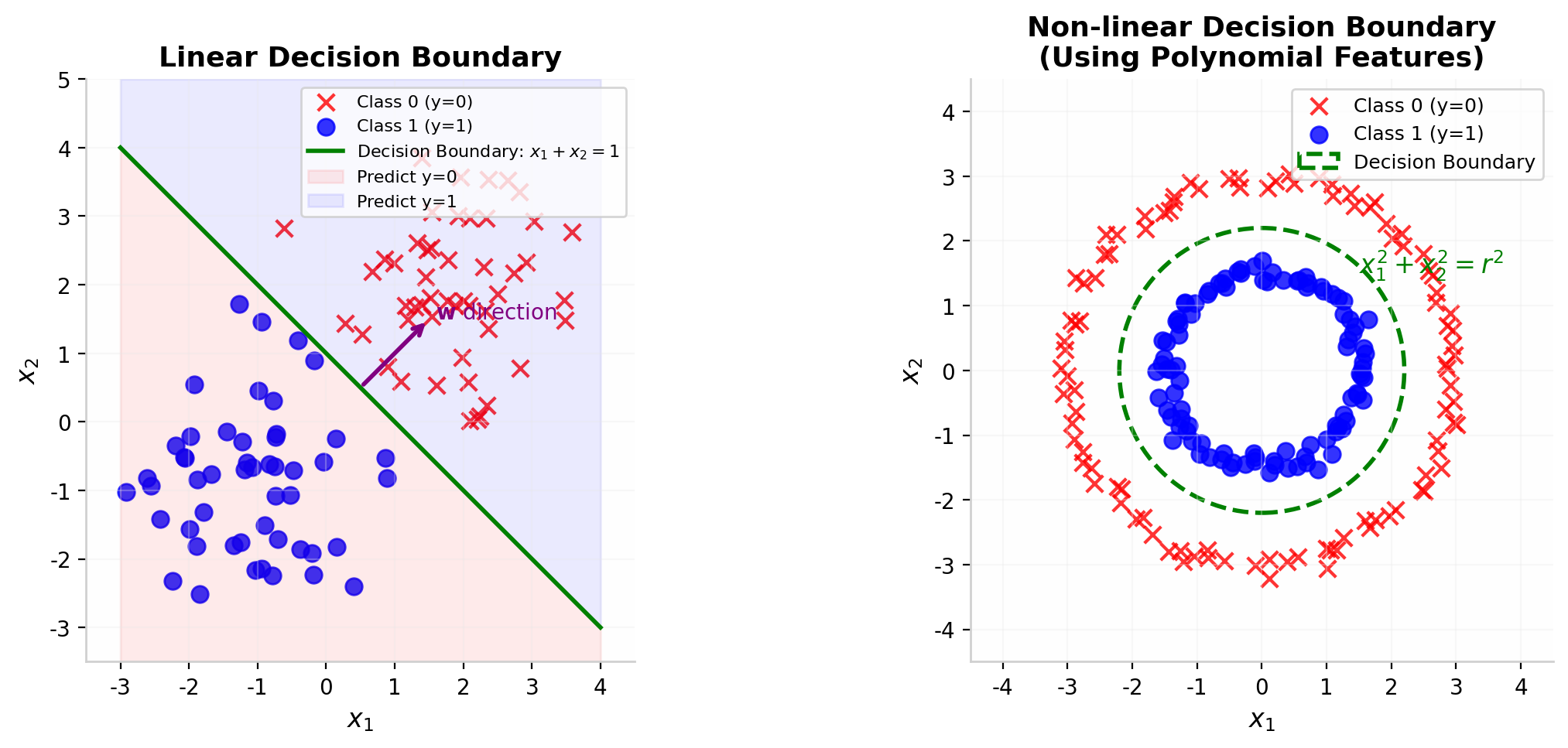
图 3 左图:线性决策边界——一条直线将两类数据分开。右图:非线性(圆形)决策边界——通过引入多项式特征 $x_1^2$ 和 $x_2^2$,可以拟合更复杂的决策边界。
通过引入更高次的多项式特征,逻辑回归可以拟合任意复杂的决策边界。但需要注意的是,特征维度的增加会带来过拟合的风险。
笔记: 特征工程 vs. 核方法
手动构造多项式特征是一种"特征工程"的方法。在更高级的算法中(如支持向量机的核方法),可以通过核函数隐式地在高维空间中操作,而不需要显式构造新特征。但逻辑回归本身不包含自动的特征映射机制,需要手动或通过其他方法进行特征构造。
4. 代价函数
4.1 为什么不能用均方误差
在线性回归中,我们常用均方误差(Mean Squared Error, MSE)作为代价函数。如果把 MSE 直接套到逻辑回归上,由于 $f(x)$ 内部包含 Sigmoid 函数,得到的优化曲面通常不再是理想的凸函数。
这会带来一个严重的问题:非凸性(Non-convexity)。代价函数可能存在许多局部最小值,梯度下降算法很容易陷入其中,无法找到全局最优解。
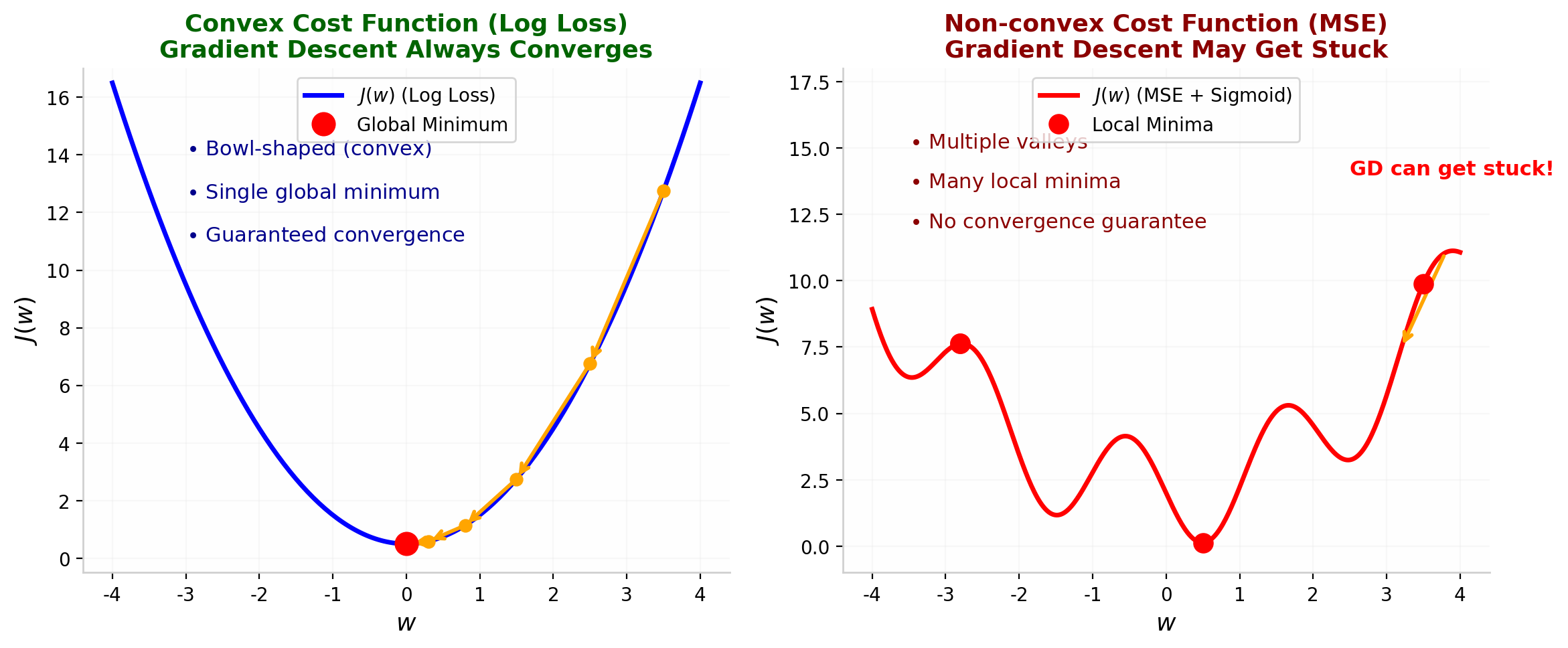
图 4 左图:对数损失是凸函数(碗状),保证梯度下降收敛到全局最优。右图:均方误差用于逻辑回归时是非凸函数(多谷底),梯度下降容易陷入局部最小值。
注意: 关键区别
线性回归的 MSE 代价函数是凸函数(碗状),保证梯度下降能收敛到全局最优。但逻辑回归中,由于 Sigmoid 的引入,MSE 变为非凸函数。因此,我们需要设计一个专门针对逻辑回归的代价函数。
4.2 对数损失函数(Logistic Loss)
逻辑回归采用对数损失函数(Log Loss),也称为交叉熵损失(Cross-Entropy Loss)。其设计思想是:当模型预测与真实标签一致时,损失很小;当预测与真实标签矛盾时,损失很大。
对于单个训练样本 $(x^{(i)},y^{(i)})$,损失函数定义为:
定义: 逻辑损失函数(单样本)
当真实标签 $y=1$ 时:
$$ \operatorname{Loss}=-\log(f(x)) $$
当真实标签 $y=0$ 时:
$$ \operatorname{Loss}=-\log(1-f(x)) $$
让我们分析这个损失函数的直观含义:
- 当 $y=1$ 时:如果模型预测 $f(x)\approx 1$(预测正确),损失接近 0;如果 $f(x)\approx 0$(预测错误),损失趋近于 $+\infty$。
- 当 $y=0$ 时:如果模型预测 $f(x)\approx 0$(预测正确),损失接近 0;如果 $f(x)\approx 1$(预测错误),损失趋近于 $+\infty$。
4.3 合并的代价函数表达式
上面的分段表达可以巧妙地合并为一个式子:
$$ \operatorname{Loss}(f(x),y)=-y\cdot\log(f(x))-(1-y)\cdot\log(1-f(x)) $$
验证:当 $y=1$ 时,第二项为 0,剩下 $-\log(f)$;当 $y=0$ 时,第一项为 0,剩下 $-\log(1-f)$。
对所有 $m$ 个训练样本取平均,得到总体代价函数:
定义: 逻辑回归代价函数(平均对数损失)
$$ J(w,b)=\frac{1}{m}\sum_{i=1}^{m}\operatorname{Loss}(f(x^{(i)}),y^{(i)}) $$
代入简化版损失函数后为:
$$ J(w,b)=-\frac{1}{m}\sum_{i=1}^{m}\left[y^{(i)}\log(f(x^{(i)}))+(1-y^{(i)})\log(1-f(x^{(i)}))\right] $$
笔记: 代价函数的性质
逻辑回归的对数损失代价函数是凸函数。这意味着无论从哪里初始化参数,梯度下降都能收敛到全局最优解。这是逻辑损失相比 MSE 的核心优势。
4.4 与最大似然估计的联系
逻辑回归的代价函数并非凭空设计,它有着坚实的统计基础——最大似然估计(Maximum Likelihood Estimation, MLE)。直观地说,最小化上面的对数损失,等价于选择一组参数 $w,b$,让训练集中真实标签出现的概率尽可能大。
定义: 结论
最小化逻辑回归的对数损失代价函数,等价于进行最大似然估计。
5. 优化:梯度下降
5.1 梯度下降更新规则
梯度下降(Gradient Descent)是优化逻辑回归参数的核心算法。其基本思想是:沿代价函数梯度的反方向更新参数,逐步逼近最优解。
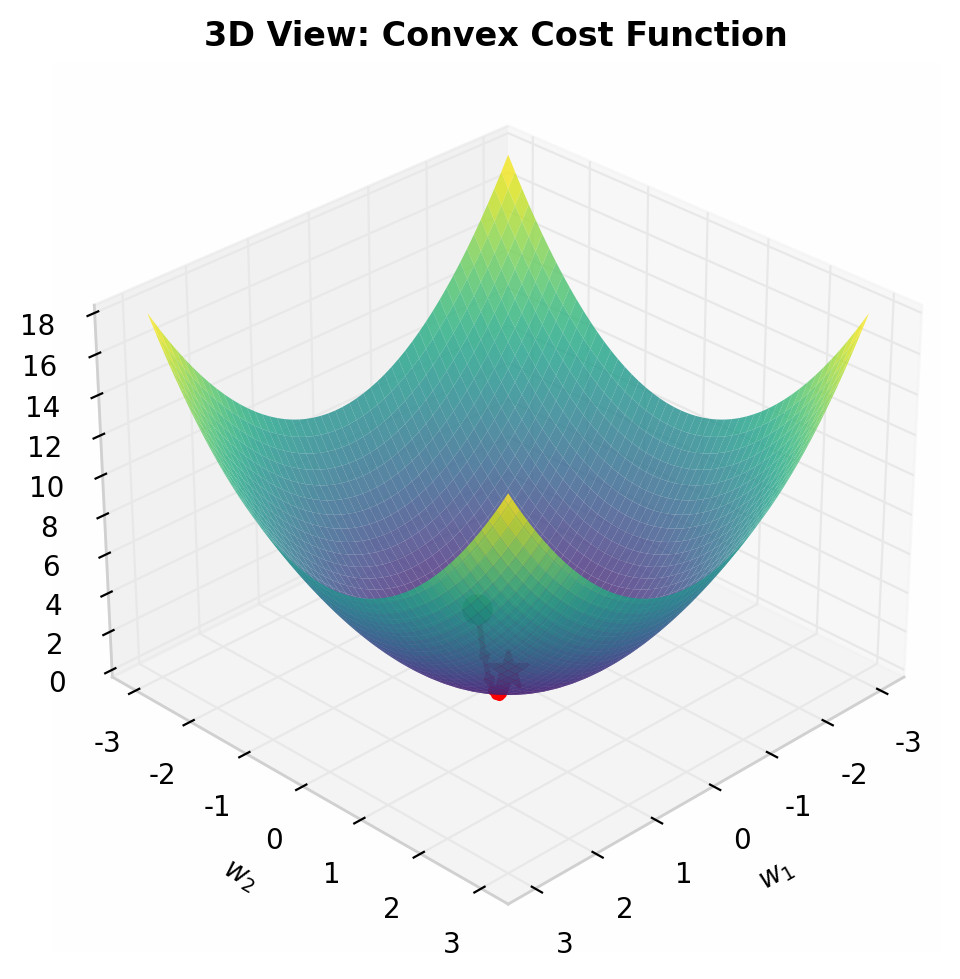
图 5 凸代价函数的 3D 碗状曲面。红色路径从起点沿最陡下降方向滚向碗底(全局最优)。由于函数是凸的,无论从哪里出发都能到达全局最优。
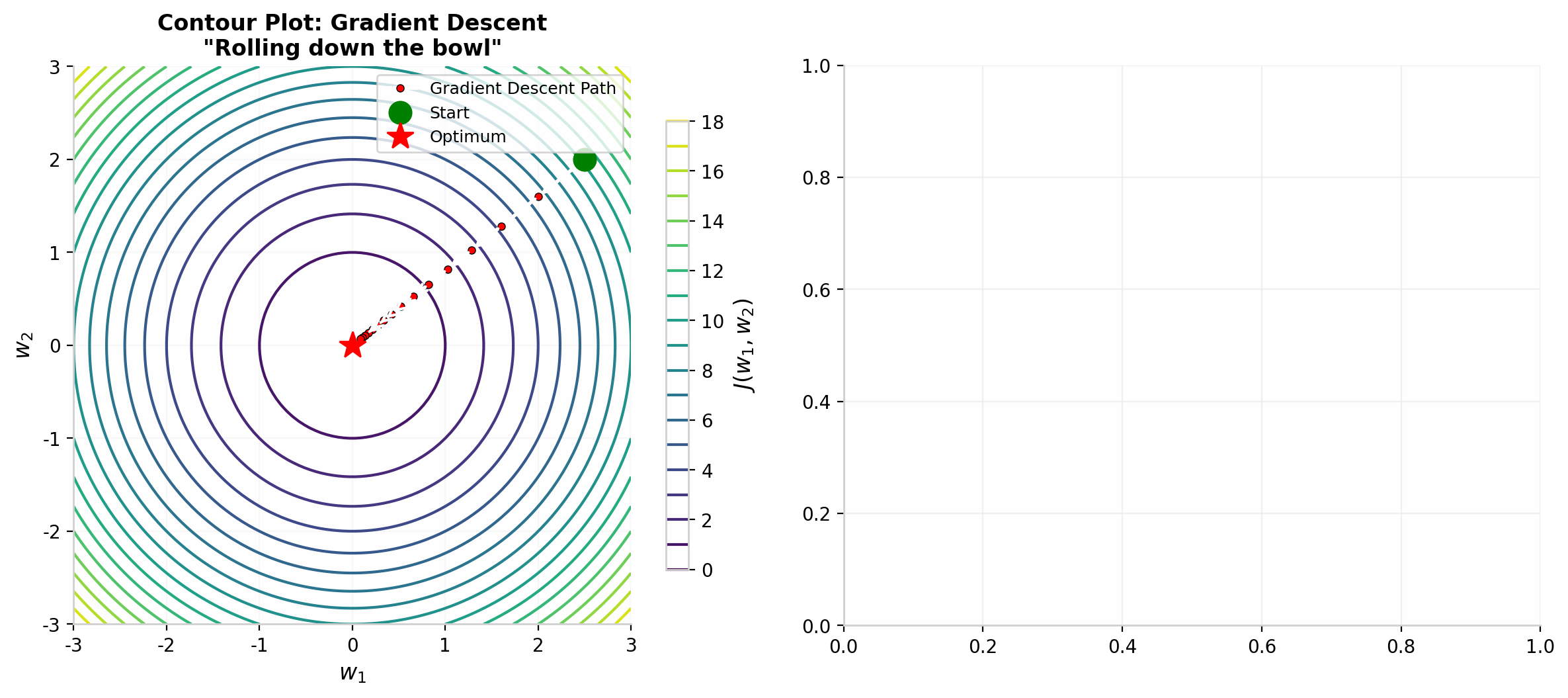
图 6 等高线视角下的梯度下降路径:参数从初始点沿着代价函数下降方向逐步靠近最优点。
首先计算代价函数对参数的偏导数。经过推导,可以得到非常简洁的结果:
定义: 梯度下降的偏导数
$$ \frac{\partial J}{\partial w_j}=\frac{1}{m}\sum_{i=1}^{m}\left(f(x^{(i)})-y^{(i)}\right)x_j^{(i)} $$
$$ \frac{\partial J}{\partial b}=\frac{1}{m}\sum_{i=1}^{m}\left(f(x^{(i)})-y^{(i)}\right) $$
笔记: 美妙的巧合
注意:逻辑回归和线性回归的更新公式在形式上完全一样,但由于 $f(x)$ 的定义不同,它们是两种不同的算法。
参数更新规则为($\alpha$ 为学习率):
定义: 梯度下降更新
梯度下降使用学习率 $\alpha$,沿着偏导数给出的下降方向反复更新参数 $w$ 和 $b$。在逻辑回归中,更新公式和线性回归形式相同,但 $f(x)$ 的定义不同。
同步更新:在每次迭代中,必须使用当前(更新前的)参数值计算所有梯度,然后同时更新所有参数。不能更新一个参数后,立即用这个新值去计算其他参数的梯度。
5.2 特征缩放的重要性
当输入特征的取值范围差异很大时(例如,房屋面积 $x_1 \in [0,2000]$ 平方英尺,卧室数量 $x_2 \in [1,5]$),代价函数的等高线会呈椭圆形而非圆形。
这会导致梯度下降收敛缓慢,甚至在狭窄的山谷中来回震荡。解决方法是特征缩放(Feature Scaling),将所有特征缩放到相似的范围内,通常是 $[-1,1]$ 或均值为 0、方差为 1 的分布。
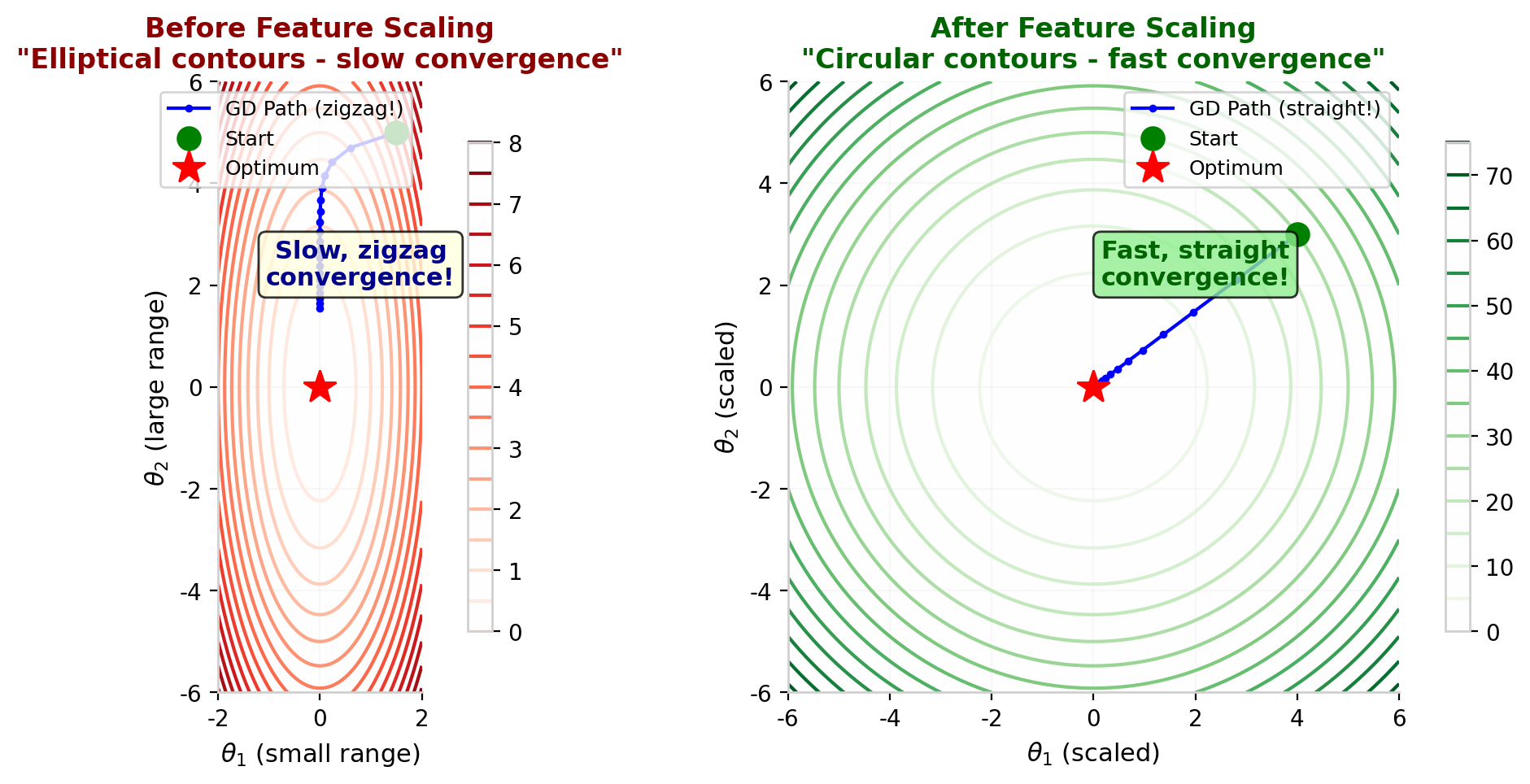
图 7 左图:未缩放时,等高线呈椭圆形,梯度下降走"之字形"路径,收敛缓慢。右图:缩放后,等高线变圆形,梯度下降沿直线快速到达最优。
定义: 特征缩放方法
常见做法包括归一化和标准化。核心目标不是改变问题本身,而是让不同特征处在相近尺度上,使梯度下降路径更直接。
5.3 向量化实现
对于大规模数据集,使用循环逐个样本计算效率低下。通过向量化(Vectorization),可以利用矩阵运算一次性处理所有样本,大幅提升计算效率。
向量化的做法是把多个样本组织成矩阵和向量,让预测、误差和梯度计算一次性完成。这样可以避免在 Python 层逐个样本循环。
笔记: 向量化的优势
现代数值计算库(如 NumPy)底层使用优化的 C/C++ 和 BLAS/LAPACK 库,能够充分利用 CPU 的 SIMD 指令和缓存机制。向量化实现通常比 Python 循环快数十到数百倍。
6. 模型拟合问题
在训练机器学习模型时,一个核心挑战是控制模型的复杂度,使其既能在训练数据上表现良好,又能泛化到未见过的数据。这涉及到三种典型的拟合状态。
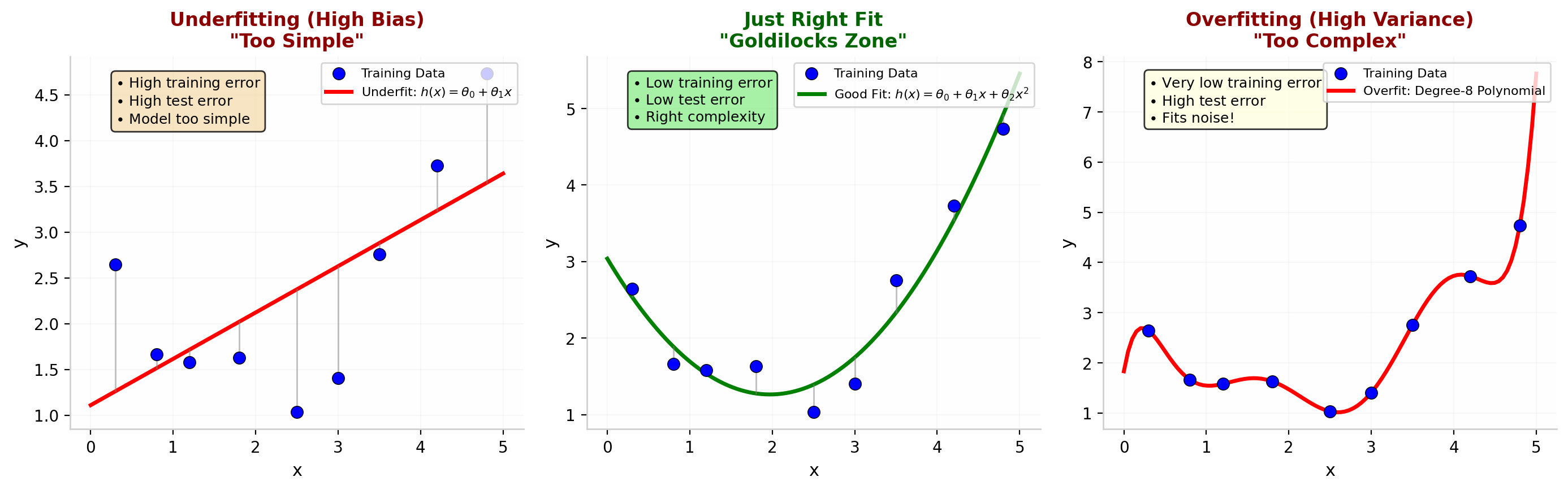
图 8 从左到右:欠拟合(直线无法拟合抛物线数据,高偏差)、适度拟合(二次曲线恰到好处)、过拟合(高阶多项式穿过每个训练点但泛化极差,高方差)。
6.1 欠拟合(高偏差)
定义: 欠拟合(Underfitting)
模型过于简单,无法捕捉数据中的规律,在训练集上表现就很差。
特征:
- 训练集误差很高
- 测试集误差同样很高
- 模型偏差(Bias)大
原因:特征太少、模型太简单(如用线性模型拟合非线性数据)、正则化过强。
示例:用一条直线去拟合明显呈抛物线分布的数据,无论怎么调整直线参数,都无法很好地拟合。
6.2 过拟合(高方差)
定义: 过拟合(Overfitting)
模型过于复杂,不仅学习了数据中的规律,还学习了噪声,导致泛化能力差。
特征:
- 训练集误差很低(甚至接近 0)
- 测试集误差很高
- 模型方差(Variance)大
原因:特征太多(尤其是高阶多项式特征)、训练数据太少、模型复杂度过高。
示例:用一个非常高阶的多项式去拟合少量数据点,曲线会穿过每一个训练点,但在新数据上表现极差。
6.3 理想的拟合状态
定义: 适度拟合(Just Right Fit)
模型复杂度适中,既充分捕捉了数据的核心规律,又没有过度拟合噪声。
特征:
- 训练集误差较低
- 测试集误差也较低,且与训练误差接近
- 偏差和方差都保持在合理水平
表 2 三种拟合状态的对比
| 状态 | 训练误差 | 测试误差 | 偏差/方差 | 典型原因 |
|---|---|---|---|---|
| 欠拟合 | 高 | 高 | 高偏差 | 模型太简单、特征不足 |
| 适度拟合 | 低 | 低 | 平衡 | 模型复杂度适中 |
| 过拟合 | 很低 | 高 | 高方差 | 模型太复杂、数据太少 |
7. 解决过拟合:正则化
过拟合是机器学习中最常见的问题之一。吴恩达在课程中介绍了三种主要的解决方案:
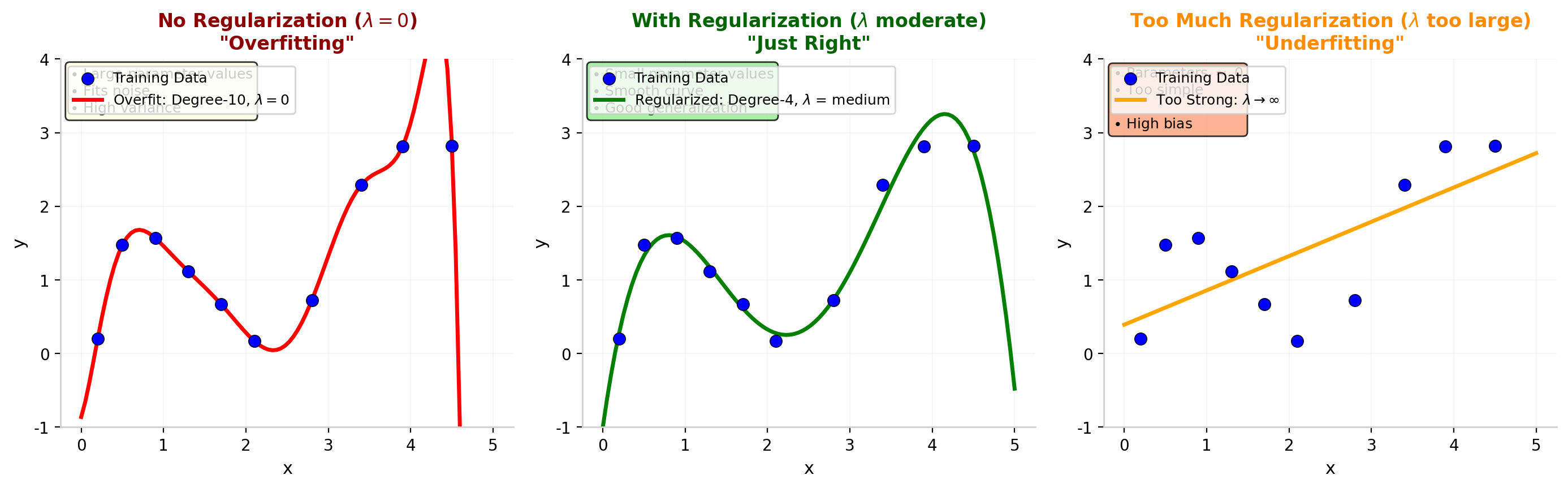
图 9 正则化参数 $\lambda$ 的三种状态。左图:$\lambda=0$(无正则化),模型过拟合训练数据。中图:$\lambda$ 适中,模型平滑且泛化良好。右图:$\lambda$ 过大,参数被过度压缩,模型欠拟合。
7.1 收集更多训练数据
更多的数据可以帮助模型学习到更通用的规律,而不是噪声。在数据量足够大的情况下,即使模型复杂度较高,也不容易过拟合。
然而,收集更多数据在很多场景下是不现实的(如医疗数据标注成本高、某些事件罕见等)。因此,我们需要其他技术手段来控制模型复杂度。
7.2 特征选择
通过分析哪些特征真正对预测有帮助,剔除冗余或不相关的特征,可以降低模型复杂度。常见方法包括:
- 手动分析:根据领域知识判断特征的重要性
- 自动特征选择算法:如前向选择、后向消除等
- 降维:如主成分分析(PCA)
特征选择的缺点是:当所有特征都有一定贡献时,简单地删除特征会损失信息。此时,更好的方法是正则化。
7.3 正则化原理
正则化(Regularization)的核心思想是:在保持所有特征的同时,限制参数的大小(即让参数尽可能小),从而降低模型复杂度,减少过拟合。
直观理解:当参数 $w_j$ 很小时,模型对输入特征的敏感度就低,曲线更加平滑,不容易被噪声干扰。
实现方法是在原有代价函数中加入一个正则化项(惩罚项):
定义: 带正则化的代价函数
$$ \frac{\lambda}{2m}\sum_{j=1}^{n}w_j^2 $$
其中 $\lambda$ 为正则化参数,$n$ 为特征数量。按照惯例,正则化项不惩罚参数 $b$。
正则化线性回归代价函数可以写成:
$$ J(w,b)=\text{MSE (均方误差)}+\frac{\lambda}{2m}\sum_{j=1}^{n}w_j^2 $$
正则化逻辑回归代价函数为:
$$ J(w,b)=-\frac{1}{m}\sum_{i=1}^{m}\left[y^{(i)}\log(f(x^{(i)}))+(1-y^{(i)})\log(1-f(x^{(i)}))\right]+\frac{\lambda}{2m}\sum_{j=1}^{n}w_j^2 $$
笔记: L1 与 L2 正则化
上面介绍的是 L2 正则化(Ridge),使用参数平方和作为惩罚项。另一种常见形式是 L1 正则化(Lasso),使用参数绝对值之和作为惩罚项。L1 正则化的特点是会产生稀疏解(部分参数变为精确的 0),自动实现特征选择。两种正则化也可以组合使用(Elastic Net)。
7.4 正则化参数 lambda
正则化参数 $\lambda \ge 0$ 控制正则化的强度,是模型训练中的超参数:
表 3 lambda 的取值影响
| lambda 取值 | 效果 | 风险 |
|---|---|---|
| lambda = 0 | 无正则化 | 可能过拟合 |
| lambda 很小 | 轻微惩罚大参数 | 欠拟合风险较低 |
| lambda 适中 | 平衡拟合与简化 | 理想状态 |
| lambda 很大 | 强惩罚,参数接近 0 | 可能欠拟合 |
| $\lambda \to \infty$ | 所有 $w_j \to 0$ | 严重欠拟合 |
lambda 的选择需要在拟合精度与模型简洁性之间做权衡。通常通过交叉验证(Cross-Validation)来选择最优的 lambda 值。
7.5 带正则化的梯度下降
在正则化代价函数下,关于 $w_j$ 的偏导数会在原来的基础上增加一项:
$$ \frac{\lambda}{m}w_j $$
因此,对应的更新公式为:
$$ w_j=w_j-\alpha\left[\frac{1}{m}\sum_{i=1}^{m}(f(x^{(i)})-y^{(i)})x_j^{(i)}+\frac{\lambda}{m}w_j\right] $$
为了更直观地理解,该公式可重写为:
$$ w_j=w_j\left(1-\alpha\frac{\lambda}{m}\right)-\alpha\left(\frac{1}{m}\sum_{i=1}^{m}(f(x^{(i)})-y^{(i)})x_j^{(i)}\right) $$
这意味着在每次更新时,先将 $w_j$ 乘以一个略小于 1 的数进行缩小。由于不惩罚 $b$,参数 $b$ 的更新规则保持不变。
8. 总结与对比
逻辑回归是机器学习中最基础且最重要的分类算法之一。下面将其与线性回归进行对比总结:
表 4 线性回归 vs. 逻辑回归
| 对比项 | 线性回归 | 逻辑回归 |
|---|---|---|
| 问题类型 | 回归(连续输出) | 分类(离散输出) |
| 输出范围 | $\hat y \in (-\infty,+\infty)$ | $f(x) \in (0,1)$(概率) |
| 假设函数 | $f(x)=\vec{w}\cdot\vec{x}+b$ | $f(x)=g(\vec{w}\cdot\vec{x}+b)$,g 为 Sigmoid |
| 代价函数 | 均方误差(MSE) | 对数损失(Log Loss / Cross-Entropy) |
| 代价函数性质 | 凸函数 | 凸函数 |
| 梯度形式 | $\frac{1}{m}X^T(f-y)$ | $\frac{1}{m}X^T(f-y)$(形式上相同) |
| 优化算法 | 梯度下降、正规方程 | 梯度下降(无闭式解) |
| 概率解释 | 高斯噪声假设下的 MLE | 伯努利分布假设下的 MLE |
| 正则化 | L1、L2 均可 | L1、L2 均可 |
逻辑回归的优点包括:模型简单、可解释性强(参数反映特征重要性)、计算高效、输出具有概率意义。它是理解更复杂分类算法(如神经网络、支持向量机)的重要基础。