Model Context Protocol (MCP) 是一个用于把 AI agents 连接到 external systems 的 open standard。把 agents 连接到 tools 和 data,传统上需要为每一组 pairing 做 custom integration,这会造成 fragmentation 和 duplicated effort,使真正 connected systems 难以 scale。MCP 提供了一个 universal protocol:developers 只需在自己的 agent 中实现一次 MCP,就能解锁整个 integrations ecosystem。
自 2024 年 11 月推出 MCP 以来,采用速度很快:community 已经构建了数千个 MCP servers,SDKs 已覆盖所有主流 programming languages,industry 也已采用 MCP 作为把 agents 连接到 tools 和 data 的 de-facto standard。
今天,developers 经常构建能访问数十个 MCP servers 上数百甚至数千个 tools 的 agents。然而,随着 connected tools 数量增长,预先加载所有 tool definitions,并通过 context window 传递 intermediate results,会拖慢 agents 并增加 costs。
在这篇 blog 中,我们会探索 code execution 如何让 agents 更高效地与 MCP servers 交互,在使用更少 tokens 的同时处理更多 tools。
随着 MCP usage scale,有两种常见 patterns 会增加 agent cost 和 latency:
- Tool definitions 使 context window 过载;
- Intermediate tool results 消耗额外 tokens。
大多数 MCP clients 会把所有 tool definitions 直接预先加载到 context 中,并用 direct tool-calling syntax 把它们暴露给 model。这些 tool definitions 可能看起来像这样:
gdrive.getDocument
Description: Retrieves a document from Google Drive
Parameters:
documentId (required, string): The ID of the document to retrieve
fields (optional, string): Specific fields to return
Returns: Document object with title, body content, metadata, permissions, etc.
salesforce.updateRecord
Description: Updates a record in Salesforce
Parameters:
objectType (required, string): Type of Salesforce object (Lead, Contact, Account, etc.)
recordId (required, string): The ID of the record to update
data (required, object): Fields to update with their new values
Returns: Updated record object with confirmation
Tool descriptions 会占用更多 context window space,增加 response time 和 costs。在 agents 连接到数千个 tools 的情况下,它们可能需要先处理数十万 tokens,然后才能读取 request。
大多数 MCP clients 允许 models 直接调用 MCP tools。例如,你可能会问你的 agent:“从 Google Drive 下载我的 meeting transcript,并把它附加到 Salesforce lead 上。”
Model 会进行这样的 calls:
TOOL CALL: gdrive.getDocument(documentId: "abc123")
→ returns "Discussed Q4 goals...\n[full transcript text]"
(loaded into model context)
TOOL CALL: salesforce.updateRecord(
objectType: "SalesMeeting",
recordId: "00Q5f000001abcXYZ",
data: { "Notes": "Discussed Q4 goals...\n[full transcript text written out]" }
)
(model needs to write entire transcript into context again)
每个 intermediate result 都必须通过 model。在这个例子中,完整 call transcript 流经了两次。对于一场 2 小时 sales meeting,这可能意味着额外处理 50,000 tokens。更大的 documents 甚至可能超过 context window limits,破坏 workflow。
对于大型 documents 或复杂 data structures,models 在 tool calls 之间复制 data 时也更可能出错。
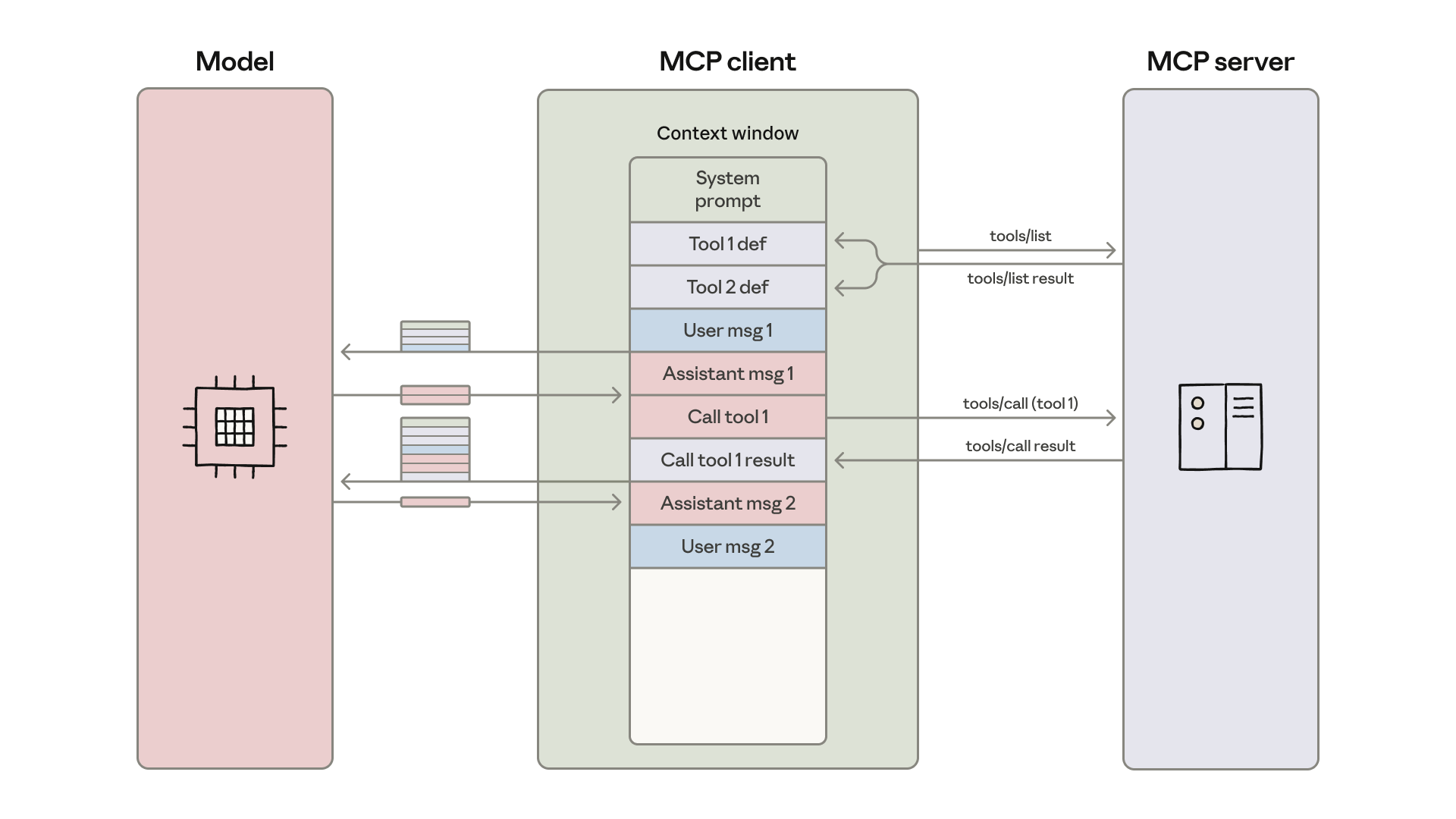
MCP client 会把 tool definitions 加载进 model 的 context window,并 orchestrate 一个 message loop,其中每次 tool call 和 result 都会在 operations 之间通过 model。
使用 MCP 进行 code execution 会提高 context efficiency
随着 code execution environments 对 agents 来说越来越常见,一个解决方案是把 MCP servers 呈现为 code APIs,而不是 direct tool calls。Agent 随后可以编写 code 来与 MCP servers 交互。这种方法同时解决了两个挑战:agents 可以只加载自己需要的 tools,并在 execution environment 中处理 data,然后再把 results 传回 model。
有很多方法可以做到这一点。一种方法是从 connected MCP servers 中的所有可用 tools 生成 file tree。下面是一个使用 TypeScript 的 implementation:
servers
├── google-drive
│ ├── getDocument.ts
│ ├── ... (other tools)
│ └── index.ts
├── salesforce
│ ├── updateRecord.ts
│ ├── ... (other tools)
│ └── index.ts
└── ... (other servers)
// ./servers/google-drive/getDocument.ts
import { callMCPTool } from "../../../client.js";
interface GetDocumentInput {
documentId: string;
}
interface GetDocumentResponse {
content: string;
}
/* Read a document from Google Drive */
export async function getDocument(input: GetDocumentInput): Promise<GetDocumentResponse> {
return callMCPTool<GetDocumentResponse>('google_drive__get_document', input);
}
// Read transcript from Google Docs and add to Salesforce prospect
import * as gdrive from './servers/google-drive';
import * as salesforce from './servers/salesforce';
const transcript = (await gdrive.getDocument({ documentId: 'abc123' })).content;
await salesforce.updateRecord({
objectType: 'SalesMeeting',
recordId: '00Q5f000001abcXYZ',
data: { Notes: transcript }
});
Agent 通过探索 filesystem 来发现 tools:列出 ./servers/ directory 以找到可用 servers(例如 google-drive 和 salesforce),然后读取它需要的具体 tool files(例如 getDocument.ts 和 updateRecord.ts)来理解每个 tool 的 interface。这让 agent 只加载当前 task 所需的 definitions。这会把 token usage 从 150,000 tokens 降到 2,000 tokens,节省 98.7% 的时间和成本。
Cloudflare published similar findings,把使用 MCP 的 code execution 称为 “Code Mode”。核心 insight 是一样的:LLMs 擅长编写 code,developers 应该利用这一优势,构建能更高效地与 MCP servers 交互的 agents。
使用 MCP 进行 code execution 的好处
使用 MCP 进行 code execution,让 agents 可以通过按需加载 tools、在 data 到达 model 前 filtering data,以及在单步中执行 complex logic 来更高效地使用 context。使用这种方法也带来 security 和 state management 方面的好处。
Models 非常擅长 navigating filesystems。把 tools 作为 filesystem 上的 code 呈现给 models,允许它们按需读取 tool definitions,而不是预先读取所有 definitions。
或者,可以向 server 添加一个 search_tools tool 来寻找 relevant definitions。例如,在使用上面假想的 Salesforce server 时,agent 搜索 “salesforce”,并只加载当前 task 所需的那些 tools。在 search_tools tool 中包含 detail level parameter,让 agent 能选择所需的 detail level(例如只要 name、name and description,或带 schemas 的完整 definition),也有助于 agent 节省 context 并高效找到 tools。
处理大型 datasets 时,agents 可以在返回 results 前用 code 过滤和转换 results。考虑获取一个 10,000 行 spreadsheet:
// Without code execution - all rows flow through context
TOOL CALL: gdrive.getSheet(sheetId: 'abc123')
→ returns 10,000 rows in context to filter manually
// With code execution - filter in the execution environment
const allRows = await gdrive.getSheet({ sheetId: 'abc123' });
const pendingOrders = allRows.filter(row =>
row["Status"] === 'pending'
);
console.log(`Found ${pendingOrders.length} pending orders`);
console.log(pendingOrders.slice(0, 5)); // Only log first 5 for review
Agent 看到的是五行,而不是 10,000 行。类似 patterns 也适用于 aggregations、跨多个 data sources 的 joins,或提取 specific fields,全都不会让 context window bloated。
Loops、conditionals 和 error handling 可以用熟悉的 code patterns 完成,而不是串联单独的 tool calls。例如,如果你需要 Slack 中的 deployment notification,agent 可以编写:
let found = false;
while (!found) {
const messages = await slack.getChannelHistory({ channel: 'C123456' });
found = messages.some(m => m.text.includes('deployment complete'));
if (!found) await new Promise(r => setTimeout(r, 5000));
}
console.log('Deployment notification received');
这种方法比通过 agent loop 在 MCP tool calls 和 sleep commands 之间交替更高效。
此外,能够写出并执行 conditional tree,也会节省 “time to first token” latency:agent 不必等待 model evaluate 一个 if-statement,而是可以让 code execution environment 来做这件事。
当 agents 使用 MCP 进行 code execution 时,intermediate results 默认保留在 execution environment 中。这样,agent 只会看到你明确 log 或 return 的内容,意味着你不希望与 model 分享的数据可以流经 workflow,而永远不进入 model 的 context。
对于更 sensitive workloads,agent harness 可以自动 tokenize sensitive data。例如,想象你需要把 customer contact details 从 spreadsheet 导入 Salesforce。Agent 写道:
const sheet = await gdrive.getSheet({ sheetId: 'abc123' });
for (const row of sheet.rows) {
await salesforce.updateRecord({
objectType: 'Lead',
recordId: row.salesforceId,
data: {
Email: row.email,
Phone: row.phone,
Name: row.name
}
});
}
console.log(`Updated ${sheet.rows.length} leads`);
MCP client 会拦截 data,并在它到达 model 前 tokenize PII:
// What the agent would see, if it logged the sheet.rows:
[
{ salesforceId: '00Q...', email: '[EMAIL_1]', phone: '[PHONE_1]', name: '[NAME_1]' },
{ salesforceId: '00Q...', email: '[EMAIL_2]', phone: '[PHONE_2]', name: '[NAME_2]' },
...
]
然后,当 data 在另一个 MCP tool call 中被分享时,它会通过 MCP client 中的 lookup 被 untokenized。真实 email addresses、phone numbers 和 names 会从 Google Sheets 流向 Salesforce,但永远不会经过 model。这可以防止 agent 意外 log 或 process sensitive data。你也可以用它来定义 deterministic security rules,选择 data 可以流向哪里,以及从哪里流出。
带 filesystem access 的 code execution 允许 agents 跨 operations 维护 state。Agents 可以把 intermediate results 写入 files,从而让它们 resume work 并 track progress:
const leads = await salesforce.query({
query: 'SELECT Id, Email FROM Lead LIMIT 1000'
});
const csvData = leads.map(l => `${l.Id},${l.Email}`).join('\n');
await fs.writeFile('./workspace/leads.csv', csvData);
// Later execution picks up where it left off
const saved = await fs.readFile('./workspace/leads.csv', 'utf-8');
Agents 也可以把自己的 code 持久化为 reusable functions。一旦 agent 为某个 task 开发出可工作的 code,就可以保存该 implementation 供未来使用:
// In ./skills/save-sheet-as-csv.ts
import * as gdrive from './servers/google-drive';
export async function saveSheetAsCsv(sheetId: string) {
const data = await gdrive.getSheet({ sheetId });
const csv = data.map(row => row.join(',')).join('\n');
await fs.writeFile(`./workspace/sheet-${sheetId}.csv`, csv);
return `./workspace/sheet-${sheetId}.csv`;
}
// Later, in any agent execution:
import { saveSheetAsCsv } from './skills/save-sheet-as-csv';
const csvPath = await saveSheetAsCsv('abc123');
这与 Skills 的概念紧密相关。Skills 是由 reusable instructions、scripts 和 resources 组成的 folders,供 models 在 specialized tasks 上提升 performance。向这些 saved functions 添加一个 SKILL.md 文件,就可以创建一个 models 能 reference 和 use 的 structured skill。随着时间推移,这让你的 agent 可以构建一个 higher-level capabilities toolbox,并演化出它最高效工作所需的 scaffolding。
请注意,code execution 会引入自身 complexity。运行 agent-generated code 需要一个 secure execution environment,并具备适当的 sandboxing、resource limits 和 monitoring。这些 infrastructure requirements 增加了 direct tool calls 所没有的 operational overhead 和 security considerations。Code execution 的好处,包括 reduced token costs、lower latency 和 improved tool composition,应该与这些 implementation costs 权衡。
MCP 为 agents 连接许多 tools 和 systems 提供了 foundational protocol。然而,一旦连接了过多 servers,tool definitions 和 results 就可能消耗过多 tokens,降低 agent efficiency。
虽然这里的许多问题感觉很新,例如 context management、tool composition、state persistence,但它们都有来自 software engineering 的已知 solutions。Code execution 把这些 established patterns 应用于 agents,让它们使用熟悉的 programming constructs 更高效地与 MCP servers 交互。如果你实现这种方法,我们鼓励你与 MCP community 分享你的发现。
本文由 Adam Jones 和 Conor Kelly 撰写。感谢 Jeremy Fox、Jerome Swannack、Stuart Ritchie、Molly Vorwerck、Matt Samuels 和 Maggie Vo 对本文 drafts 的反馈。